
개요
아마도 첫 파인튜닝.
llm 서비스를 만들면서 구조화한 서비스 포맷에 따라서 오픈 소스 llm을 파인튜닝해야했다.
그러다가 unsloth로 colab에서도 파인튜닝이 가능함을 알게됐고, llama 3의 서비스에서 사용하는 체인들의 json 스키마에 따라 잘 못 만드는 것을 확인하여 이를 해결해야만 했다.

CODE
위 코드는 Unsloth에서 공개한 코드의 일부분을 수정한 것이다.
(아직 llama 3.1을 이 코드 기반으로 파인튜닝하는 것을 완료되지 않았음 10/05/24)
파인튜닝
핵심: Unsloth 기반 LoRA 튜닝
가난한 자를 위한 프레임워크인 Unsloth를 활용하여 빠르게 튜닝해보자. 다행인 것은 Colab에서 바로 Unsloth로 튜닝이 가능했다는 점이다. Unsloth 깃헙이나 페이지에 들어가면 튜토리얼이 나오고, 이를 참고하면 된다.
코드는 다른 참고한 블로그나, Unsloth의 코드를 참고하여 작성했다. ipynb 파일은 아래에 첨부해두겠다.
•
본 포스트에서 허깅페이스로 업로드하는 것은 다루지 않는다.
전체 과정 흐름
1.
Colab에서 Unsloth로 파인튜닝 후 modelfile과 gguf 파일 다운로드
a.
모델 파일은 unsloth에서 자동으로 생성함
2.
llm을 서빙할 서버에서 ollama 프로세스 실행
3.
기존 랭체인 ChatOllama 를 활용하여 기존 프로세스에 통합
1. Colab에서 Unsloth로 파인튜닝 후 modelfile과 gguf 파일 다운로드
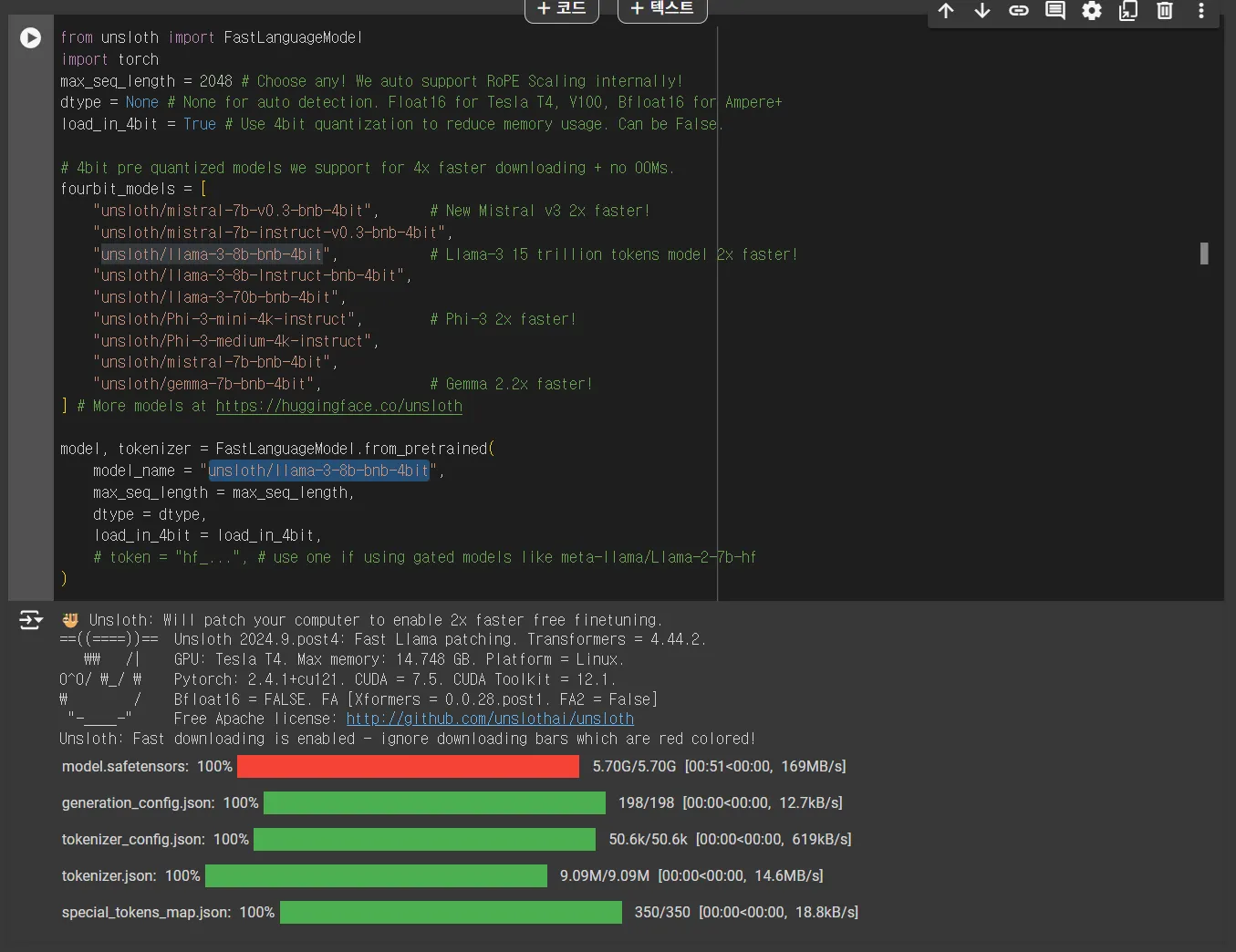
우선적으로 모델을 불러온다.
이후, chat_template을 설정하고 alpaca dataset을 템플릿에 맞춰서 변환한다.
어차피 자동으로 해주니 그대로 코드 실행하면 문제가 없음
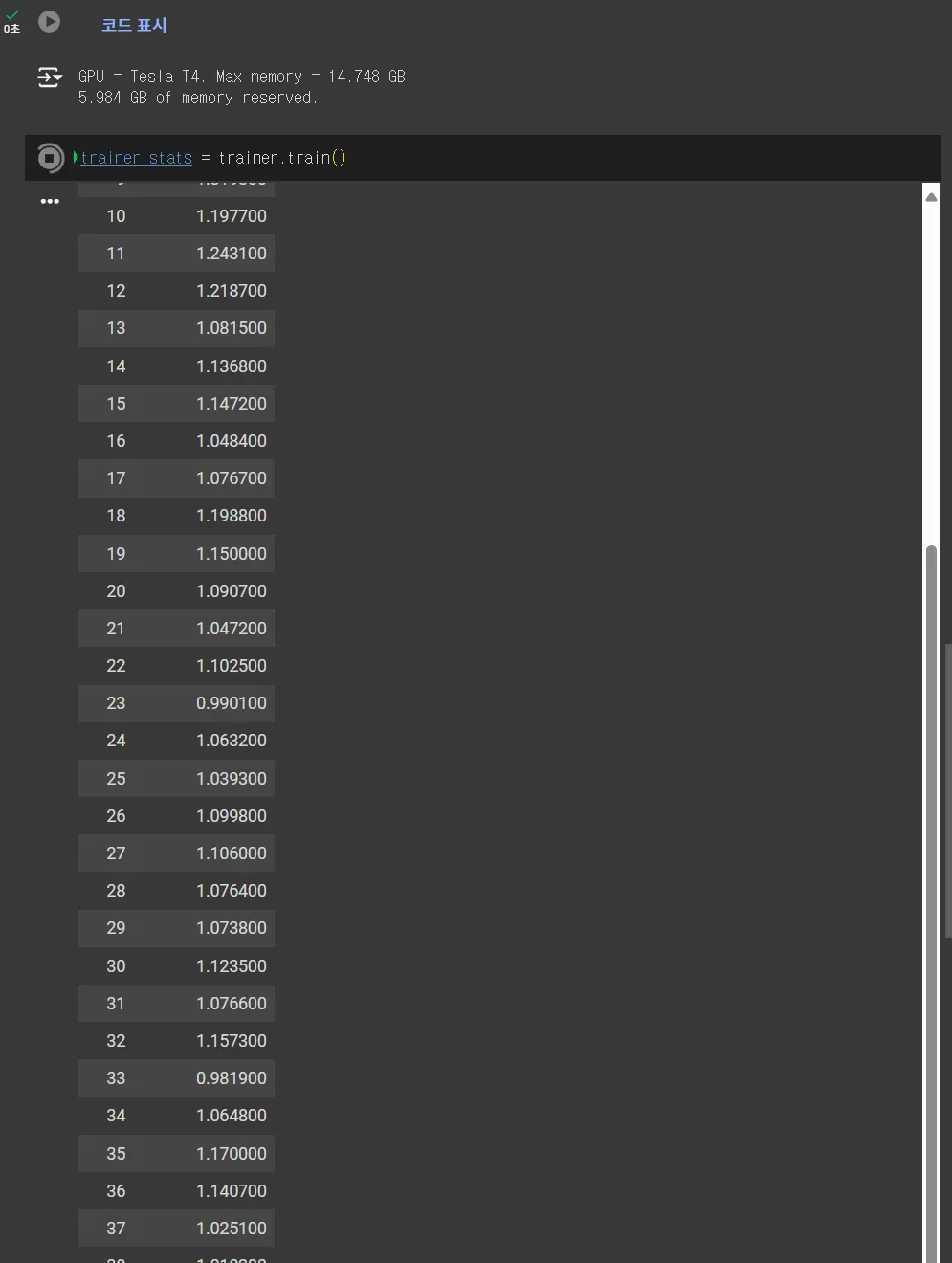
모델 학습을 거쳐주고,

이후 완성된 모델을 gguf 파일로 변환 후 다운로드
폴더를 코랩에 model 폴더에 들어가보면 있을 것이다.
학습시킨 8B 모델이라도 8gb 정도의 파일 크기다. 코랩에서 다운 받는 데에도 상당한 시간이 걸림.
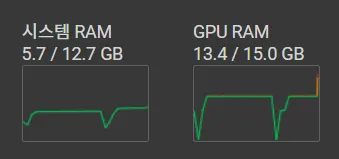
학습시 GPU는 사실 … GPU가 터지는 경우도 있었지만 T4라서 겨우겨우 버텨준다 (가끔은 부족한 경우나, 어학습 중에 컴퓨팅 세션이 끊기는 경우도 있어서 잘 봐줘야한다.
2. llm을 서빙할 서버에서 ollama 프로세스 실행
서버에 ollama가 설치됐다는 가정 하에, Modelfile과 gguf 파일을 다운로드 받아 서버에 옮겨놓고 아래 사ㅓ진의 명령어를 실행한다.

위 사진은 코랩 노트북 사진이므로 !를 없애고 쉘에서 치는건 당연한 이야기.
이후, ollama에 모델이 올라갔을 것이다.

ollama serve로 백그라운드 서버를 실행하고, ollama list 등으로 모델이 잘 올라가있는지 확인해주자.
3. 기존 랭체인 ChatOllama 를 활용하여 기존 프로세스에 통합
다행히 랭체인에 모델을 넣는 것은 정말 쉽다.
ChatOllama 클래스를 사용하여 모델을 부르면, ollama로 돌고 있는 서버가 알아서 모델 파일을 로드해주는 것으로 보인다.
예시는 랭체인 공식 사이트에 있는 코드를 비슷하게 사용하면 된다. 내 코드는 회사 코드라 공개하기가 조금 그래서..
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="llama3.1",
temperature=0,
# other params...
)
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that translates {input_language} to {output_language}.",
),
("human", "{input}"),
]
)
chain = prompt | llm
chain.invoke(
{
"input_language": "English",
"output_language": "German",
"input": "I love programming.",
}
)
Go
복사
Langchain 의 체인을 만든 다음에 invoke 로 프롬프트 템플릿을 채워서 체인을 실행하거나, 간단한 입력으로 하면 끝.
결론
•
결국은 Colab에서 Unsloth로 파인튜닝을 해주고, gguf 파일을 다운로드 하여 Ollama가 설치된 서버에 넣고 실행시켜서 LangChain의 ChatOllama 클래스로 모델을 불러오면 끝.
•
Colab + Unsloth 사랑해요.
Trouble Shooting
첫번째 난관
•
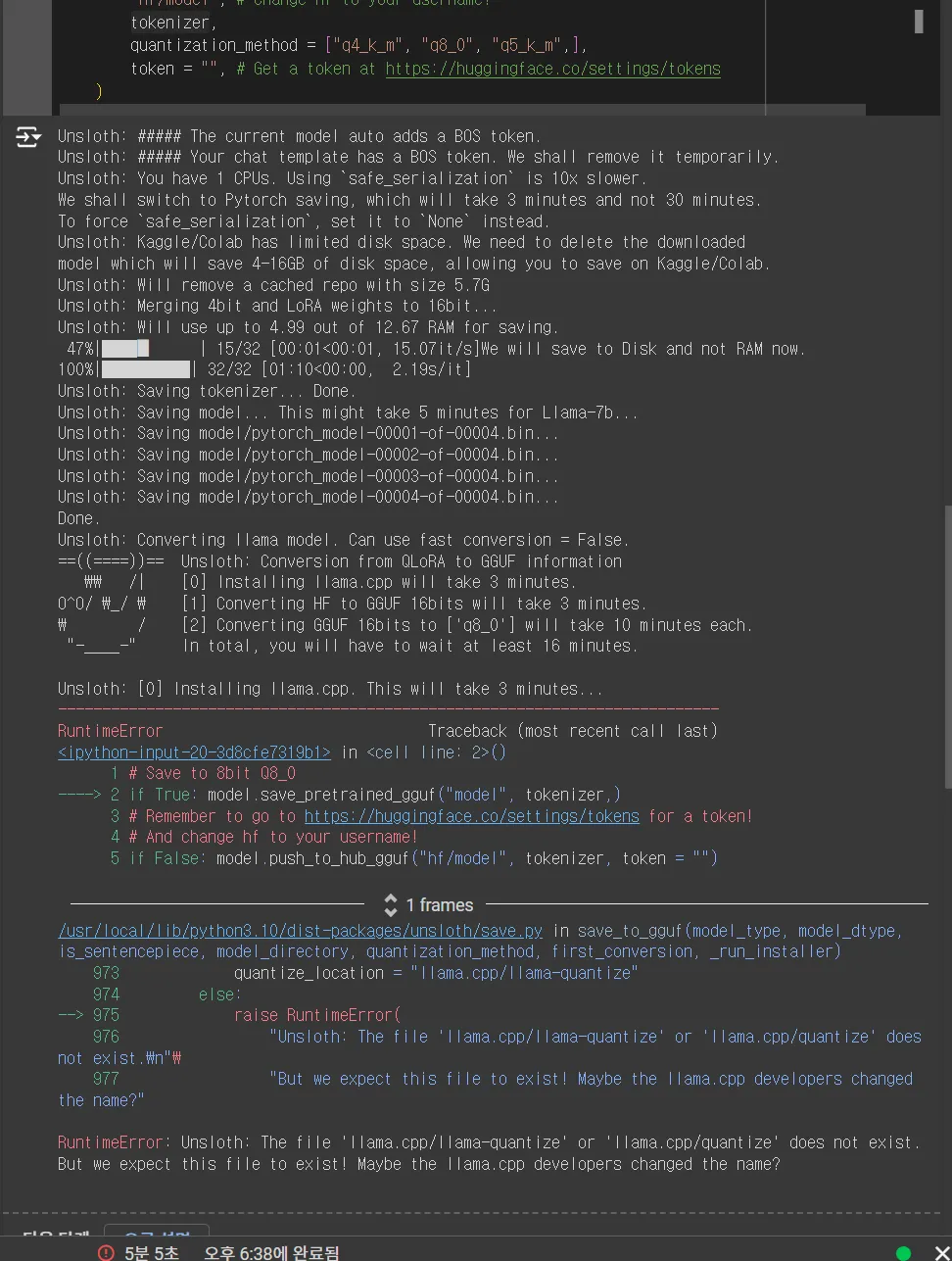
q4_k_m으로 양자화 시도 시 llama.cpp quantize 파일 못 찾음
◦
3.1 튜닝 시 발생하는 문제로 보임 (10/05/24 해결 과정 진행 중)
◦
3.0에서는 제대로 작동함
1.
코랩을 다시 실행해서 하니까 또 될 때가 있더라.
2.
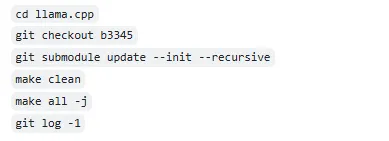
다시 문제가 생기면 라마 C++을 다시 재설치해볼 수 있을 것으로 판단했음
◦
이 문제는 두 가지로 풀 수 있는 것으로 보인다. (어느 것으로 해도 상관 없음)
1.
cd llama.cpp 명령어를 치고, make 명령어로 컴파일을 하면 된다
두번째 난관
•
chat_template을 instruct 모드로 바꿨을 때, 생기는 문제
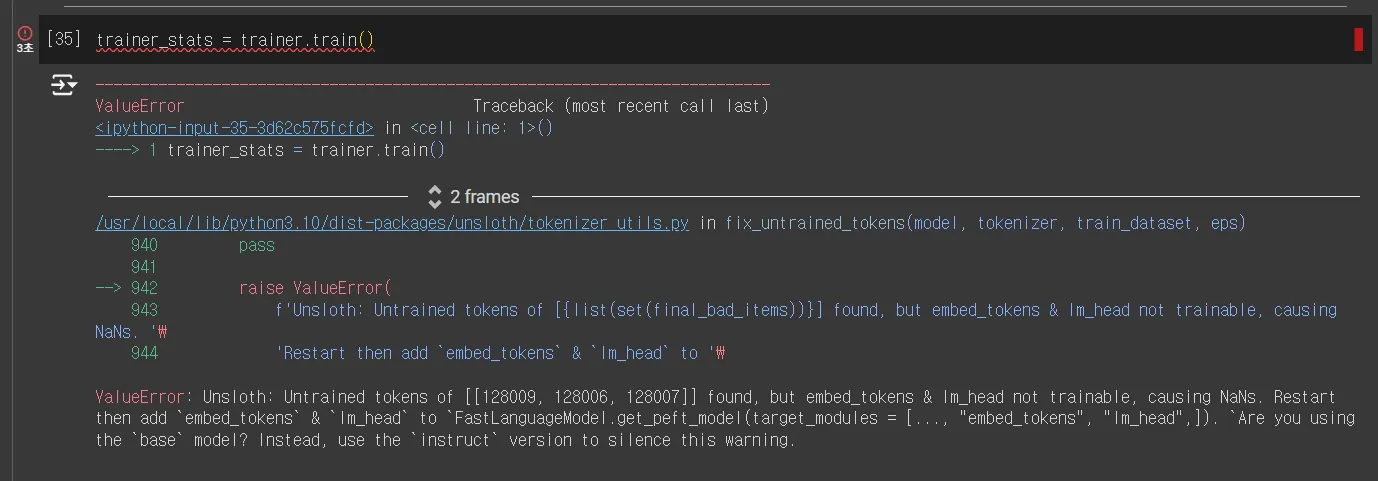
◦
해결책: Instruct 모델로 바꿔준다.
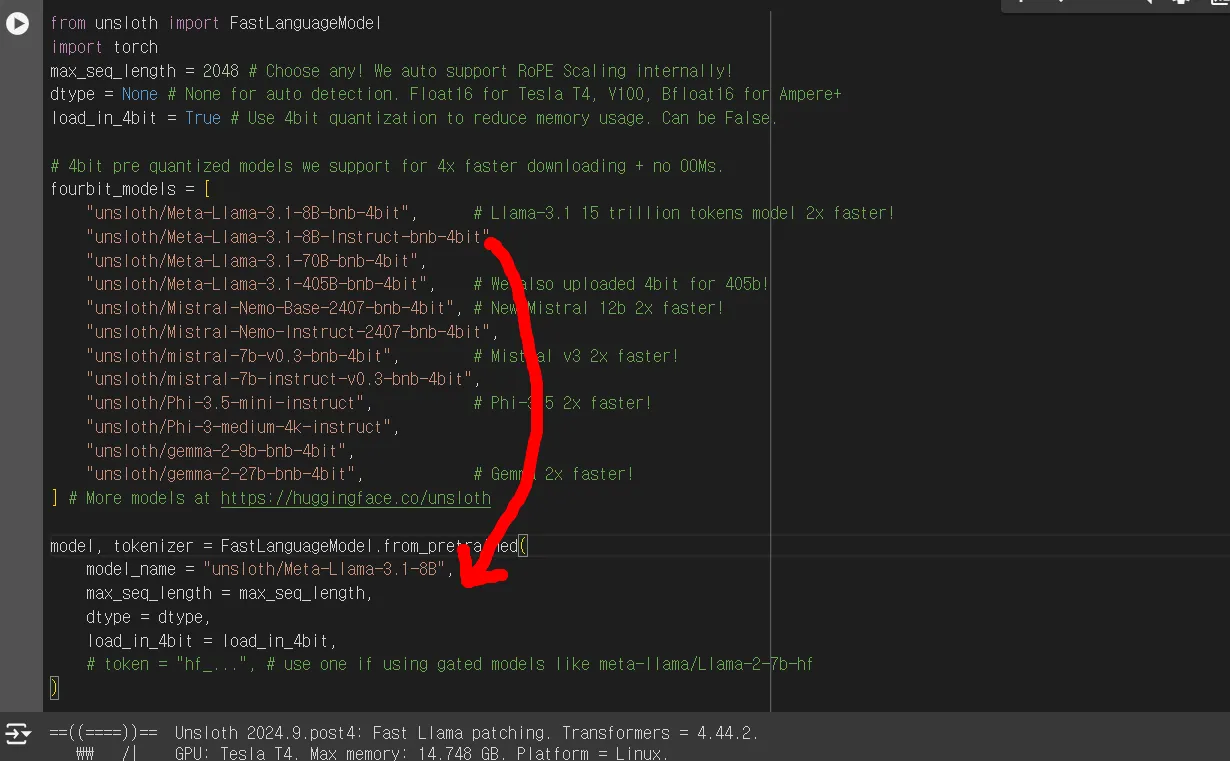
잘 돌아가는 것을 확인할 수 있다.