Abstract
•
Problems of existing retrieval-augmented approaches
◦
most existing methods retrieve only a few short, contiguous text chunks
▪
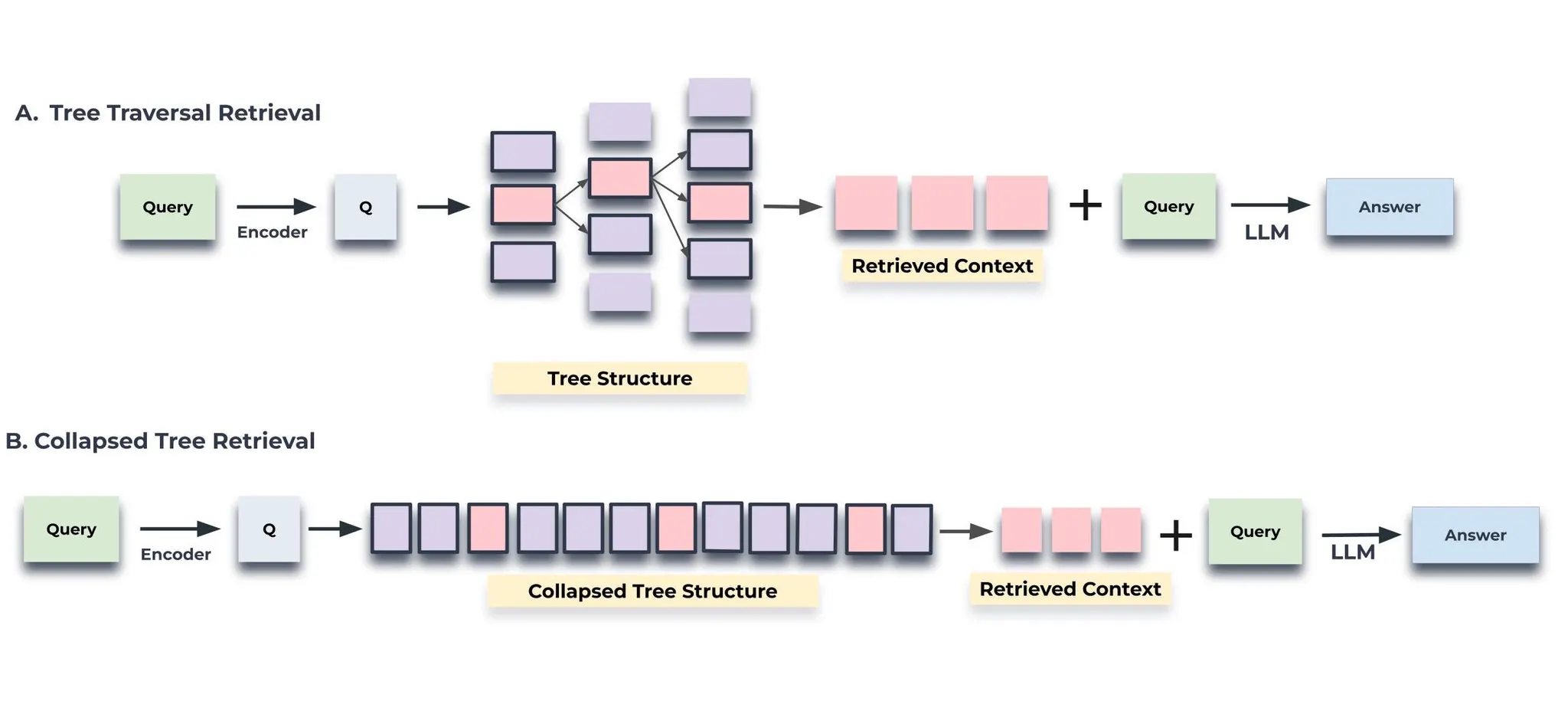
Authors designed an indexing and retrieval system that uses a tree structure to capture both high-level and low-level details about a text.
•
selecting the most relevant information for knowledge-intensive tasks is still crucial.
Background
•
Recursive Summarization as Context
◦
The recursive-abstractive summarization model by Wu et al. (2021) employs task decomposition to summarize smaller text chunks, which are later integrated to form summaries of larger sections.
◦
While this method is effective for capturing broader themes, it can miss granular details. LlamaIndex (Liu, 2022) mitigates this issue by similarly summarizing adjacent text chunks but also retaining intermediate nodes thus storing varying levels of detail, keeping granular details.
◦
may still overlook distant interdependencies within the text
Method
Tree Contrection Process
•
RAPTOR recursively clusters chunks of text based on their vector embeddings and generates text summaries of those clusters, constructing a tree from the bottom up. Nodes clustered together are siblings; a parent node contains the text summary of that cluster.
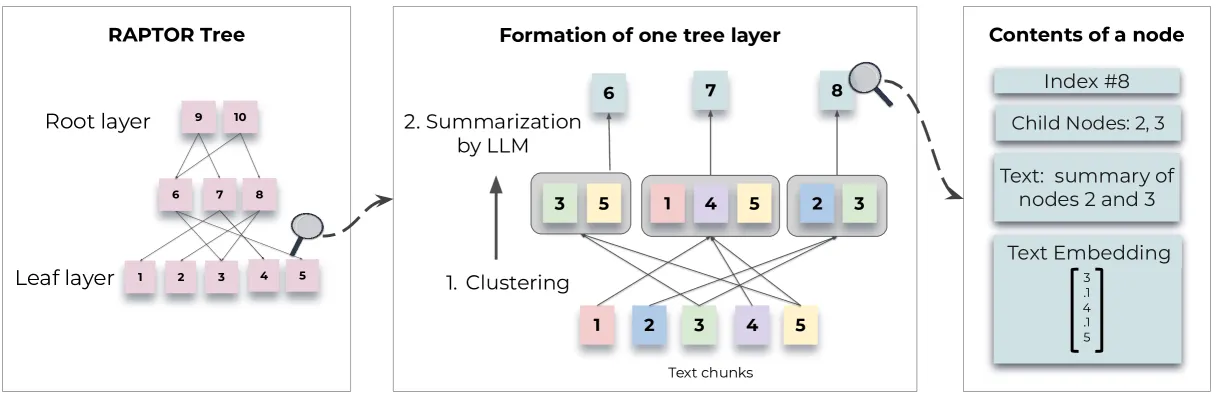
The clustering approach in tree construction includes a few interesting ideas.
GMM (Gaussian Mixture Model)
•
Model the distribution of data points across different clusters
•
Optimal number of clusters by evaluating the model's Bayesian Information Criterion (BIC)
UMAP (Uniform Manifold Approximation and Projection)
•
Supports clustering
•
Reduces the dimensionality of high-dimensional data
•
UMAP helps to highlight the natural grouping of data points based on their similarities
Local and Global Clustering
•
Used to analyze data at different scales
•
Both fine-grained and broader patterns within the data are captured effectively
Thresholding
•
Apply in the context of GMM to determine cluster membership
•
Based on the probability distribution (assignment of data points to ≥ 1 cluster)