Abstract
This week’s lab meeting explores recent advancements in Hierarchical, Part-based, and Physics-aware 3D Scene Graphs, focusing on how functional and physical reasoning can enrich 3D scene understanding for robotics and generative modeling. In the first part, we review emerging methods such as FunGraph (IROS 2025) and Open-Vocabulary Functional 3D Scene Graphs (CVPR 2025) that extend traditional 3D scene graphs beyond object-level spatial relationships to incorporate intra-object and functional connections—enabling robots to identify and interact with manipulable elements (e.g., handles, switches). We also highlight ConceptGraphs (ICRA 2024) and HiKER-SGG (CVPR 2024) as approaches that introduce open-vocabulary and hierarchy-aware reasoning, increasing robustness and scalability in real-world environments.
The second part investigates Physics-aware and Causal Scene Graphs that integrate physical laws and causal reasoning into 3D perception. Methods such as PhiP-G (Arxiv 2025), HoloScene (NeurIPS 2025), and PhyRecon aim to generate physically plausible 3D scenes and interactive digital twins by combining large language models, Gaussian Splatting, and physics simulation. Complementary work like TRAVL (2025) focuses on improving video-language models’ ability to judge physical implausibility via trajectory-guided attention mechanisms.
Through comparative analysis, we identify a key trend: Scene Graphs serve as the essential intermediate representation linking perception, functionality, and physical simulation—critical for real-time robotic understanding and generative 3D modeling. The discussion concludes with potential research directions for integrating functional reasoning with physics-based constraints and benchmark creation for evaluating physical understanding in vision-language models.
1. Hierarchical and Part-Based Scene Graphs

•
Part-based scene graphs explicitly model objects and their subcomponents (e.g., a chair’s legs, seat, backrest), enabling more detailed reasoning about object structure.
1.1 FunGraph (IROS 2025)
Introduction
•
3D Scene Graph → 기존에는 객체 수준에 초점
•
기능적인 요소들 (Functional Elements, e.g. 손잡이, 스위치) 을 기존 방법들은 이를 무시
•
FunGraph는 객체 내부 관계 (intra-object relationships)를 포함하여 3DSG를 확장
Related Work
•
3DSG Generation and Prediction
◦
기존 방식은 객체 수준에서 멈추며, 작은 부품이나 상호작용 가능한 구성요소는 제외됨.
◦
일부 연구는 객체 부품을 고려했으나, functinality 까지 반영한 예는 거의 없음.
•
Alternative Queryable Scene Representations
◦
NeRF, Gaussian Splatting 등도 사용되지만, 작은 기능성 요소 (e.g. 손잡이, 스위치) 의 표현에 부적합한 면이 있음
◦
Search3D는 파트 수준 표현이 가능하지만, 기능성에 대한 의미적 관계가 부족함.

•
Functionality Segmentation & Affordance Understanding
◦
PartNet, 3D AffordanceNet 등의 데이터셋은 Gibsonian affordance에 기반.
◦
SceneFun3D는 기능성 요소에 대한 3D Comments을 제공하는 최초의 실내 장면 데이터셋으로 사용됨
Method
•
Problem Formulation
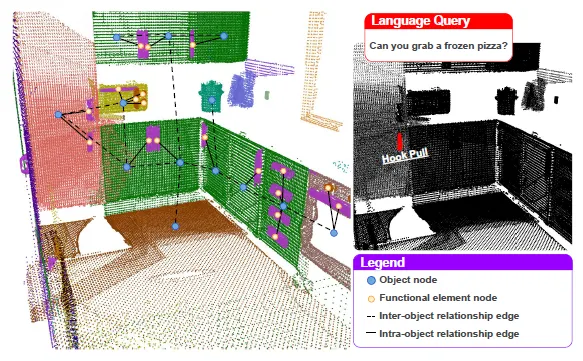
This work aims to extend the classical pipeline of 3D scene graph generation for indoor environments by incorporating intra-object relationships between scene objects (referred to
as “objects” in the following) and their 3D functionally interactive elements (referred to as “functional elements” in the following).
→ 기존 3DSG에 객체 기능성 요소 관계 (intra-obejct edge)를 추가하여, 로봇이 어떤 부품을 통해 어떤 기능을 수행할 수 있는지 학습 가능케 함
기능성 요소 관계 (intra-obejct edge)를 추가하여, 로봇이 어떤 부품을 통해 어떤 기능을 수행할 수 있는지 학습 가능케 함•
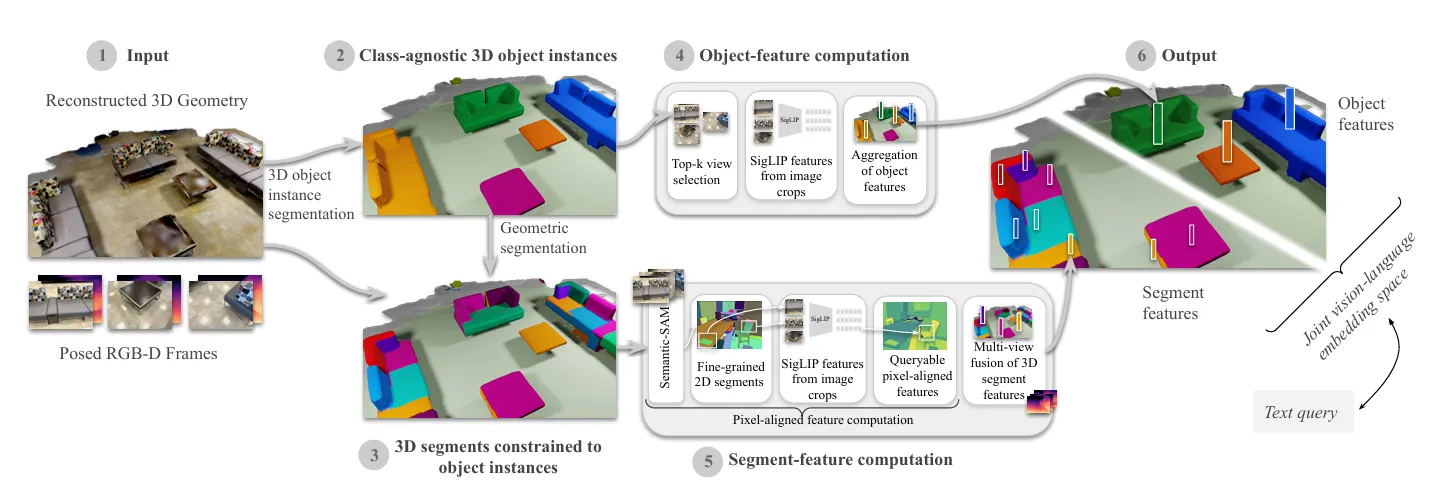
Generation of 2D Data
◦
RGB-D observations as input, propose to detect functional elements from high-resolution RGB
▪
3D SG → YOILO-WORLDv8.2 for object detection and RT-DETR
▪
Semantic Segmentation → SAM2 and as VLM GPT-4o
•
Functionality Aware 3D Scene Graph Generation
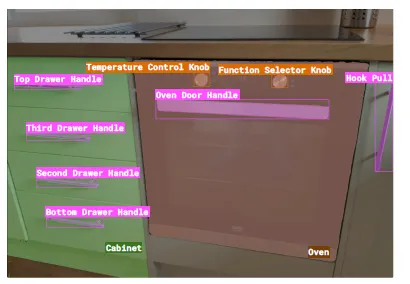
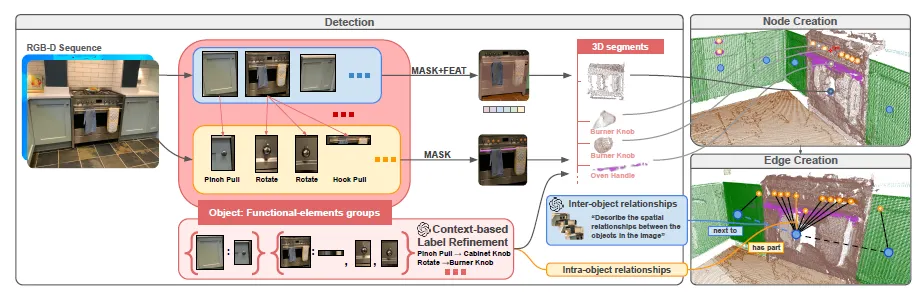
The handle on the right, labeled “Hook Pull,” is not linked to any object, and, as a result, cannot be refined further.
◦
전체 파이프라인은 3단계:
1.
Detection: 객체 및 기능성 요소를 2D 이미지에서 탐지.
2.
Node Creation: 여러 시점의 RGB-D를 통해 3D 노드 생성.
3.
Edge Creation: 공간적 관계 및 기능적 관계 정의.
◦
GPT-4o를 활용하여 기능성 요소에 affordance label 붙이고, 필요 없는 것은 label refinement을 진행
Experiemts
•
Detecting Functional Interactive Elements in Images
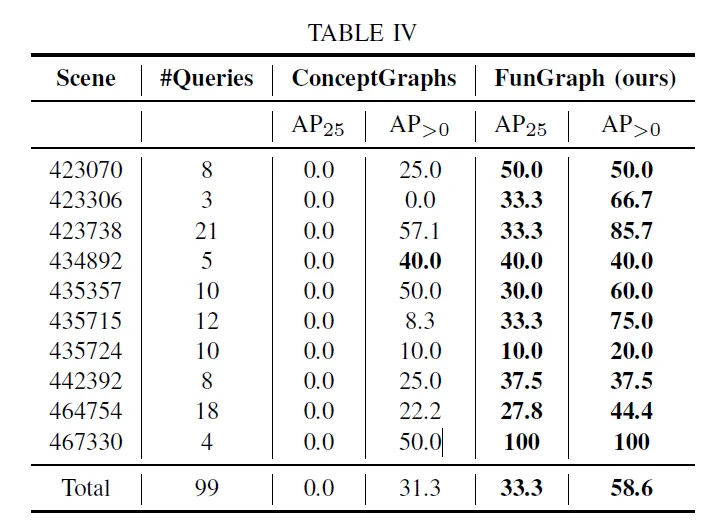
•
언어 기반 명령(예: “쓰레기통 열기”)에 대해 적절한 기능성 요소를 그래프에서 찾아 반환.
•
기능성 요소 명명 정확도: GPT-4o + context 사용 시 가장 높음 (정확도 78%).
To obtain also a semantically meaningful label, we prompt GPT-4o with each group of object and its associated functional elements in the image. We call this approach “GPT-Context” to highlight that the model is aware of the intra-object relationship.
Limitations
하나의 기능성 요소가 여러 객체에 연결될 수 있는 상황에 대한 표현 한계 존재.
•
예를 들어 drawer of the cabinet, the knob to the cabinet
Conclusion
•
객체 내부 관계를 포함하는 3D Scene Graph를 제안하여, 로봇이 언어를 기반으로 환경과 상호작용할 수 있도록 만듦
1.2. Open-Vocabulary Functional 3D Scene Graphs (CVPR 2025)
Introduction
•
기존의 3D Scene Graph는 주로 객체 간의 공간적 관계(spatial relationships)만을 표현.
•
그러나 실제 환경에서는 조작 가능한 요소(예: 스위치, 손잡이)와 그 기능적 관계가 중요함.
•
이를 해결하기 위해 Functional 3D Scene Graph를 도입.
•
핵심 아이디어: 객체뿐 아니라 조작 가능한 부품(interactive elements)과 기능적 관계(Functional Relations)를 함께 그래프 구조로 모델링.
Related Work
•
1.1 과 비슷한 Related Work
Method
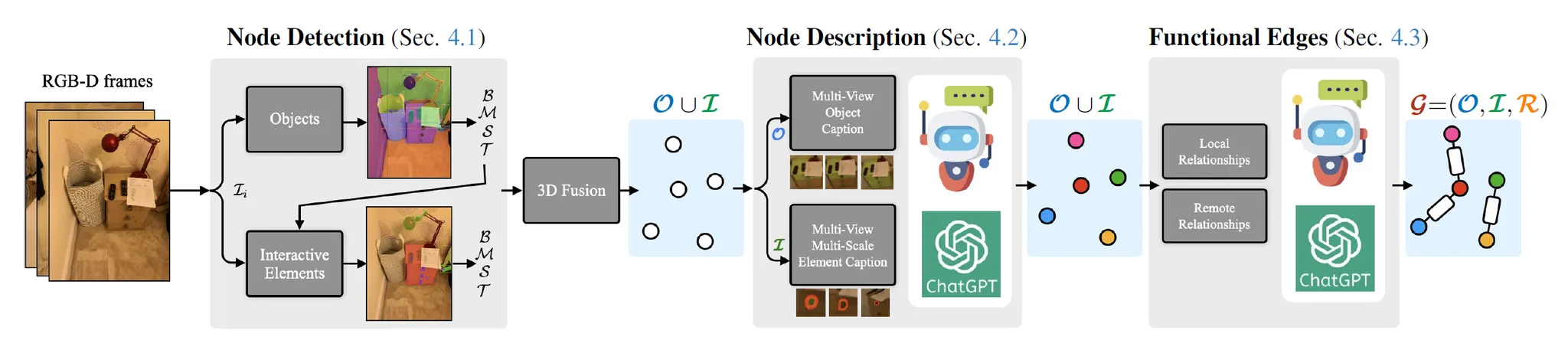
•
기능 관계 유형:
◦
Local: 객체와 부품이 물리적으로 붙어 있음 (예: 문-손잡이)
◦
Remote: 물리적으로 떨어져 있지만 기능적으로 연결 (예: 리모컨-TV)
•
Open-vocabulary pipeline 기반으로 특정 태스크에 의존하지 않고 다양한 기능 관계를 추론.
•
주요 단계:
1.
Node Detection (4.1): RAM++과 GroundingDINO로 객체 및 부품 탐지
2.
Node Description (4.2): LLAVA + GPT를 활용하여 자연어 설명 생성
3.
Functional Edge Inference (4.3):
•
Sequential reasoning: local 관계부터 시작 → remote 관계로 확장
•
GPT와 LLAVA의 상식 지식을 활용해 관계 추론
4.
Final Graph Formation (4.4): 전체 그래프 통합
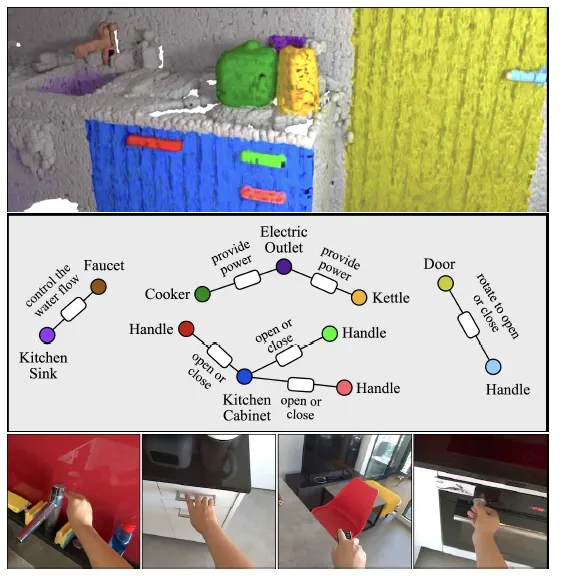
Experiemts

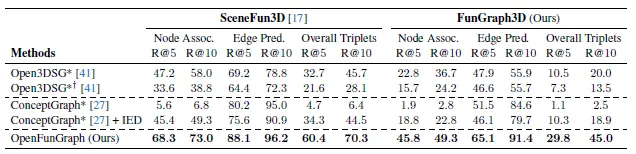
조작 부품 인식과 원격 관계 추론에서 강력한 성능
•
기능 부품 탐지 프롬프트 제거 시 성능 하락
•
Sequential reasoning 제거 시 triplet 예측 정확도 급감
Conclusion
•
Functional 3D Scene Graph는 실내 장면의 동작 가능성과 기능적 관계를 효과적으로 표현할 수 있는 새로운 방법.
•
Open-vocabulary 접근으로 범용성 확보
1.3. HiKER-SGG (Zhang et al., CVPR 2024)
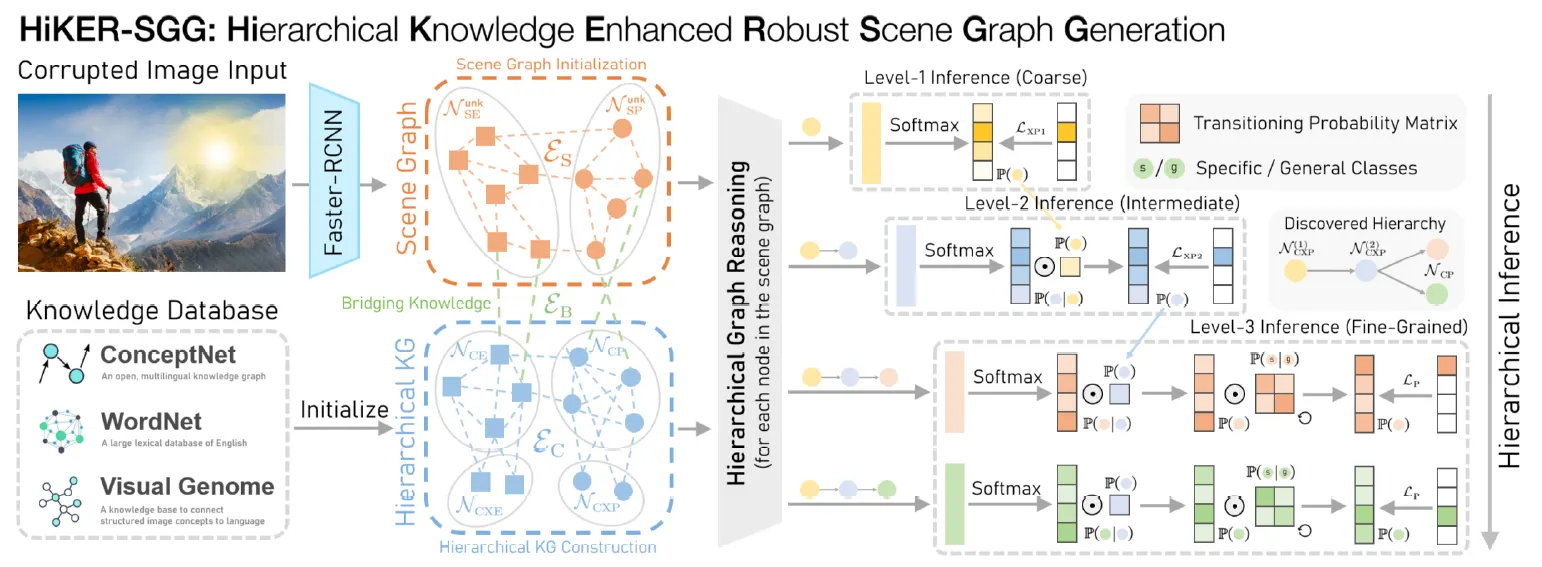
Introduction
기존 연구들은 ‘깨끗한(clean) 이미지’를 전제로 학습하며, 실제 환경에서 발생하는 노이즈·날씨·빛 반사(glare)·먼지 등 시각적 손상(corruption) 상황에서는 성능이 급격히 저하됨 → Robust 한 모델이 필요
Related Work
•
Knowledge-based SGG: 외부 지식그래프(ConceptNet 등)를 활용해 관계 예측 정확도를 높임.
Method
•
객체나 관계를 한 번에 세밀하게 분류하지 않고, 상위(superclass) → 하위(subclass) 단계로 점진적 추론을 수행.
•
GloVe 임베딩 + 혼동 행렬 기반 유사도를 활용해 객체 및 관계의 계층 구조(superclass-subclass)를 자동 구성.
1.4. ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning (ICRA 2024)
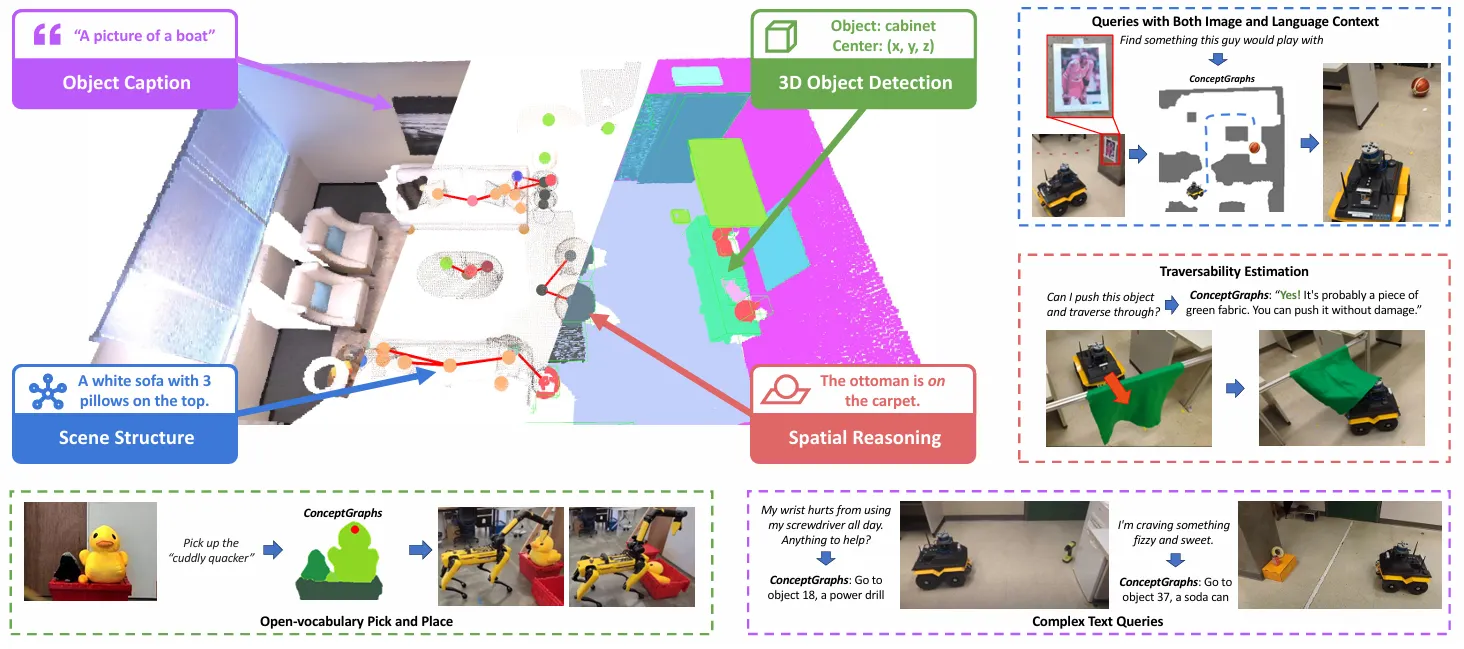
Introduction
Open-Vocabulary 기반의 3D Scene Graph를 생성하여 로봇이 인식과 계획을 수행할 수 있도록 함
Related Work
•
기존 3D 장면 표현은 주로 닫힌 어휘(closed vocabulary)와 점 기반(dense point-based) 표현에 의존해 확장성과 유연성이 부족함.
•
ConceptGraphs는 클래스에 구애받지 않는 객체 기반(object-centric) 표현을 통해 장면을 그래프로 구조화하고, 대형 비전-언어 모델(VLM)과 대형 언어 모델(LLM)을 활용해 객체와 관계를 자동으로 주석화(captioning)함.
Method
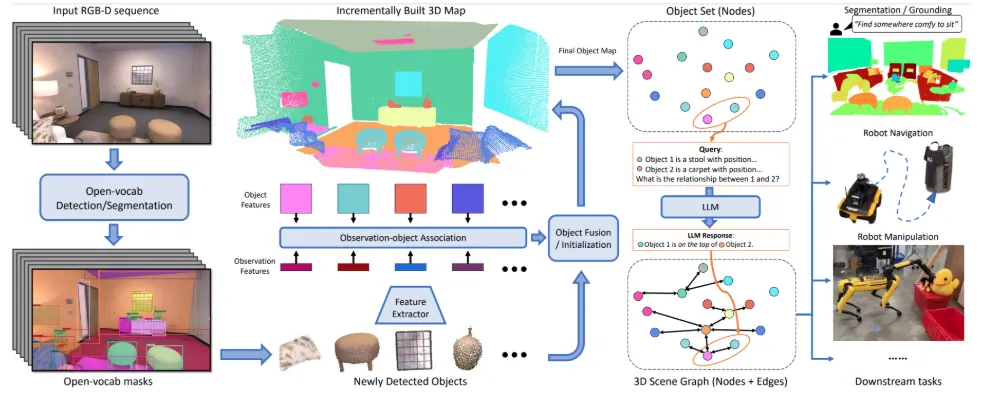
•
Object-based 3D Mapping
◦
입력: 연속적인 RGB-D 이미지와 포즈 정보.
◦
Segmentation: Segment Anything Model (SAM) 등으로 객체를 분리.
◦
Feature Extraction: CLIP, DINO 등을 통해 각 객체에 대한 시각 특징 추출.
◦
Object Association & Fusion: 새로운 객체가 기존에 존재하는 객체와 유사하면 병합, 아니면 새 객체로 추가.
◦
Captioning: 여러 시점의 이미지에서 얻은 캡션을 LLM(GPT-4)을 통해 하나의 일관된 설명으로 통합.
•
Scene Graph Generation
◦
노드: 객체.
◦
엣지: 객체 간 공간적 관계(예: "의자가 테이블 아래에 있음").
◦
관계 추론: LLM을 통해 관계 문장을 자연어로 생성.
•
Task Planning via LLM
◦
JSON 포맷의 장면 정보를 LLM에 입력 → 자연어 쿼리 처리.
◦
예: "something to sit on" → 관련 객체 추출 및 위치 제공.
Experiemts
사람 평가자(AMT)를 통해 캡션 정확도, 중복 객체 수, 관계 정확도 평가.
•
평균 노드 정확도 71%, 관계 정확도 88%.
복잡한 언어 쿼리 처리 가능 (예: 부정 포함, 추상적 표현).
Limitations
•
LVLM 기반 캡션 생성 오류 발생 가능 (특히 작은/얇은 물체).
◦
→ 2025 년 이후에 나온 논문에서 기능적 요구사항과 함께 Yolo 등 Obejct Detection 모델도 실험을 같이 한 부분이 있는데, 이것이 아무래도 인식 성능 자체도 중요해서 그런가 아닌가하는 의견
•
다수의 LLM/LVLM 호출로 인해 연산 비용이 큼.
•
추후 더 나은 LVLM이나 hierarchy-aware LLM planner로 보완 가능.
2. Physics-Aware and Causal Scene Graphs
HoloScene and Structured-NeRF treat the scene graph as the backbone for enforcing physical laws in 3D reconstruction
generative models to probe physics
causal inference techniques are being repurposed to improve scene graphs
•
3D 객체 생성 부분 / Video Generation에서 물리 법칙을 이해하는가? 에 대한 연구가 최근 이뤄지고 있음.
◦
방향은 두 개로 판단,
▪
3D 객체 생성에 대한 물리적 관계를 보완할 것인가?
▪
Video Generation 모델로 갈 것인가? (이 문제는 보통 Spatio-Temporal Continuity 라고 불리는 것으로 보임)


2.1. PhiP-G: Physics-Guided Text-to-3D Compositional Scene Generation (Arxiv 2025)
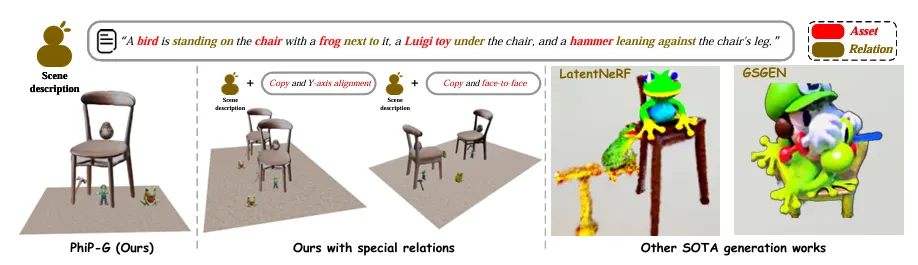
Introduction
기존 Text-to-3D 모델은 개별 객체 생성에는 성과가 있었지만, compositional scene generation (복합 3D 장면 구성) 에서는 다음과 같은 한계가 있음:
•
생성된 장면의 배치가 물리 법칙에 부합하지 않음
•
텍스트에 언급된 객체 간 관계를 제대로 포착하지 못함
•
대형 언어 모델(LLMs)을 사용하더라도 자율적인 3D Asset 생성이 어려움
Method
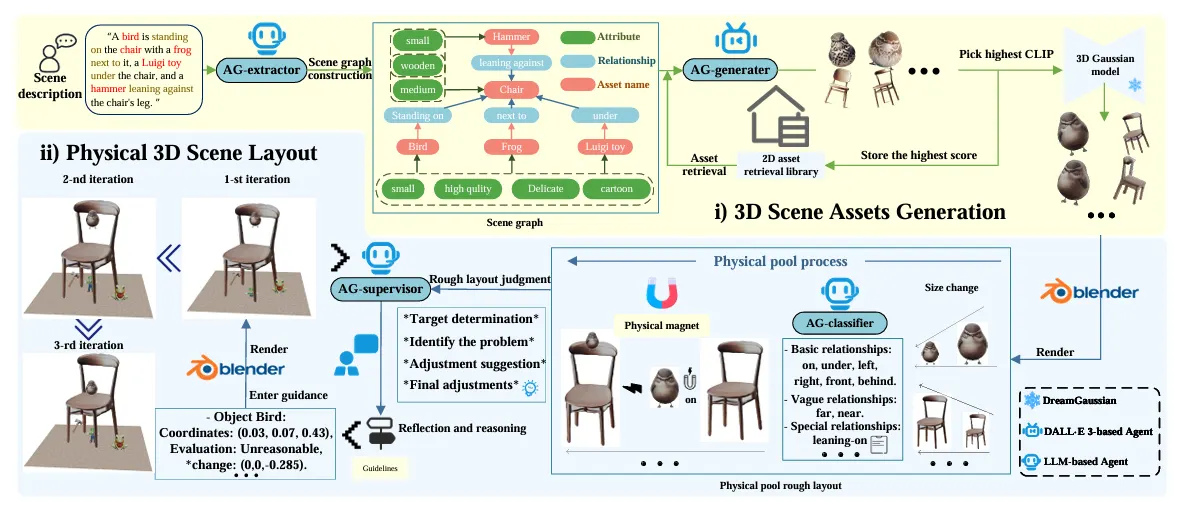
•
PhiP-G Framework
◦
3D Asset Generation
▪
텍스트에서 Scene Graph를 추출
▪
DALLE 3 기반의 2D 이미지 생성 에이전트
▪
DreamGaussian 모델을 활용하여 3D Gaussian Splatting 기반의 자산 생성
▪
CLIP Score를 사용하여 텍스트-이미지 일치도를 평가하여 최적의 이미지 선택
◦
이후, 물리 기반 장면 배치 (Physical layout Planning)
▪
Pysical Pool: 객체 간 물리 관계 정리 및 초기 배치
▪
Physical Magnet: 객체 접촉 위치를 실제처럼 보정

▪
AG-Supervisor: 시각적 평가 및 반복 피드백을 통해 레이아웃 세부 조정
•
to match the inter-asset relationships with the relational database
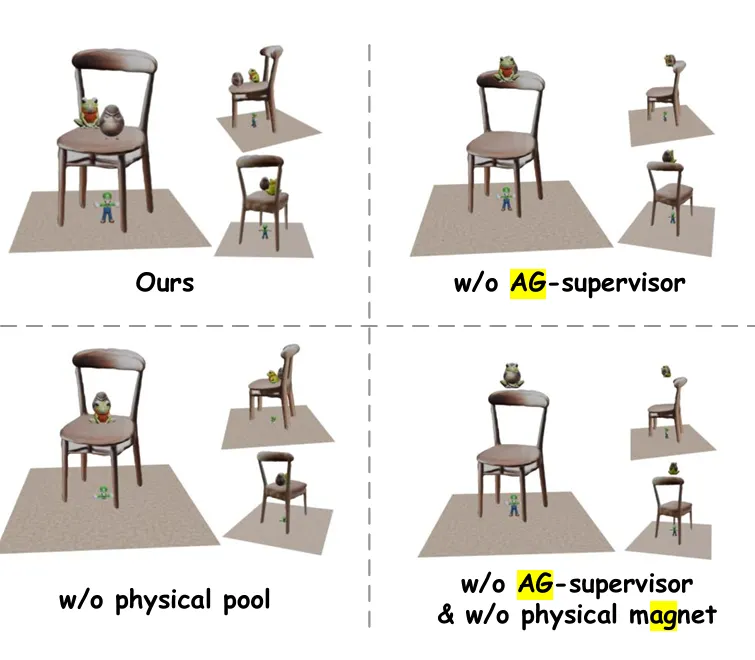
Experiemts

Conclusion
•
PhiP-G는 LLM 기반 다중 에이전트 시스템과 3D Gaussian Splatting 기법을 결합하여 기존 방식의 한계를 극복하며 빠르고 물리적으로 타당한 고품질 3D 장면 생성을 실현
2.2. HoloScene (NeurIPS 2025)
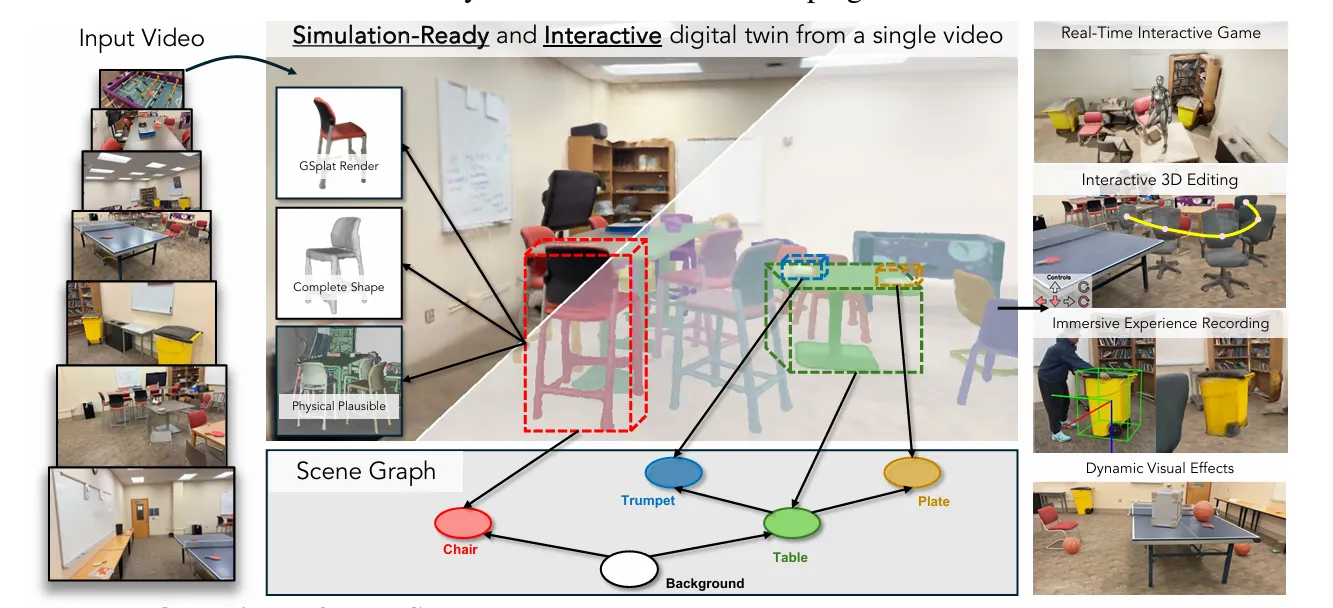
Introduction
단일 비디오 입력으로부터 시뮬레이션 가능한(interactive & physically plausible) 3D 디지털 트윈(scene graph 기반)을 재구성하는 새로운 프레임워크
•
기존 3D Reconstruction은 Geometric Completeness, 물리적 타당성, 사실적 렌더링에 집중하고 있었음
•
Scene Graph를 통해 객체의 형상, 물성, 외형, 상호 관계를 통합 표현이 가능
◦
→ 시각 복원뿐만 아니라 상호작용 가능한 구조와 시뮬레이터 기반 물리적 안정성을 보장하는 프레임워크라고 주장
Method
•
각 객체는 다음으로 구성됨:
◦
형상 (geometry): Neural SDF + mesh (Marching Cubes)
◦
외형 (appearance): Gaussian Splatting
◦
물리 속성 (physics): 질량, 마찰, 반발계수 등
◦
상태 (state): 위치/회전 정보
•
객체 간 관계: 지지(support), 접촉(beside), 충돌(collision)
•
최적화 목표
◦
형상 완성도 (E_comp): Wonder3D 기반 가상 관측으로 보정
◦
형상 일관성 (E_geo): 객체 간 침투 방지
◦
물리적 안정성 (E_physics): 중력 시뮬레이션 상 안정 상태
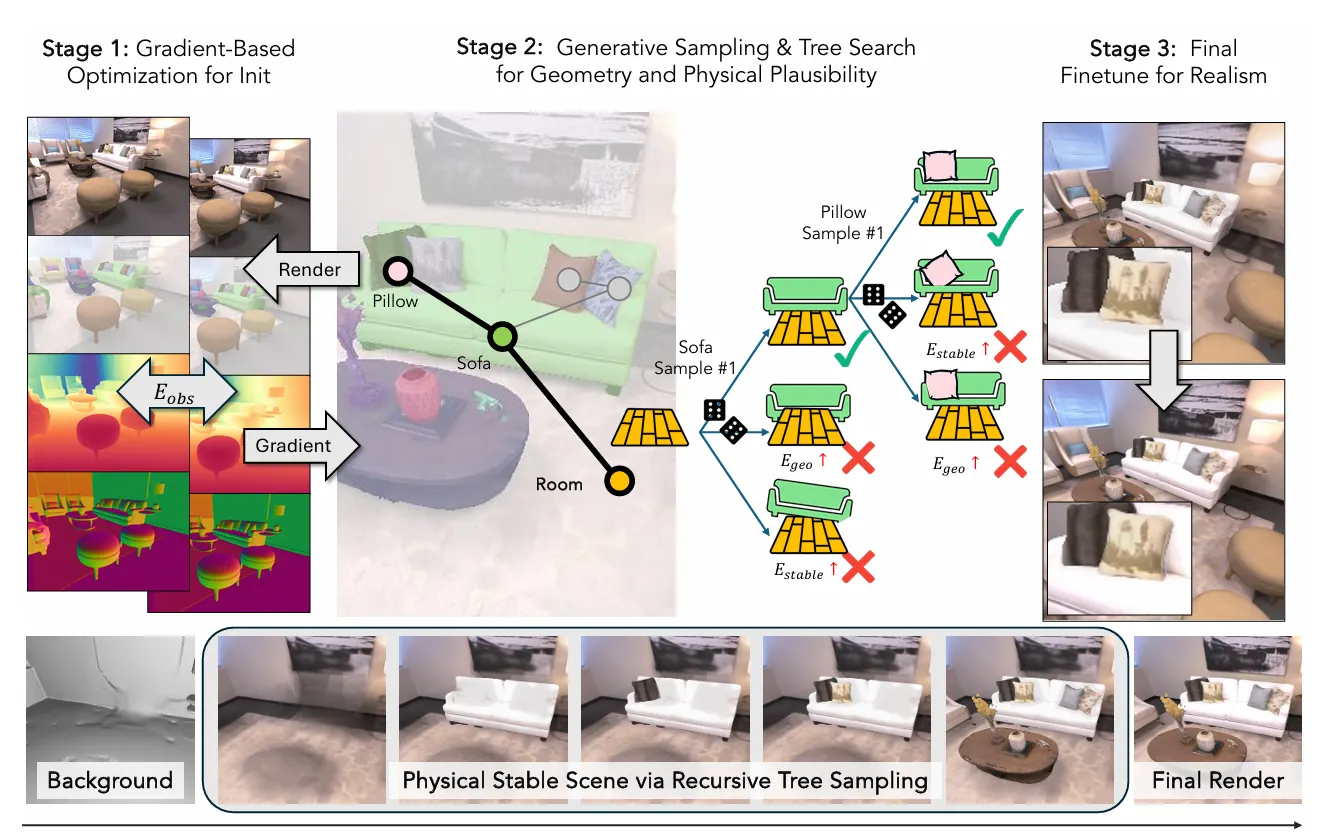
Experiemts

Limitations
HoloScene은 정적 실내 장면에 특화되어 있으며, 동적 장면 또는 야외 환경에는 적용 어려움.
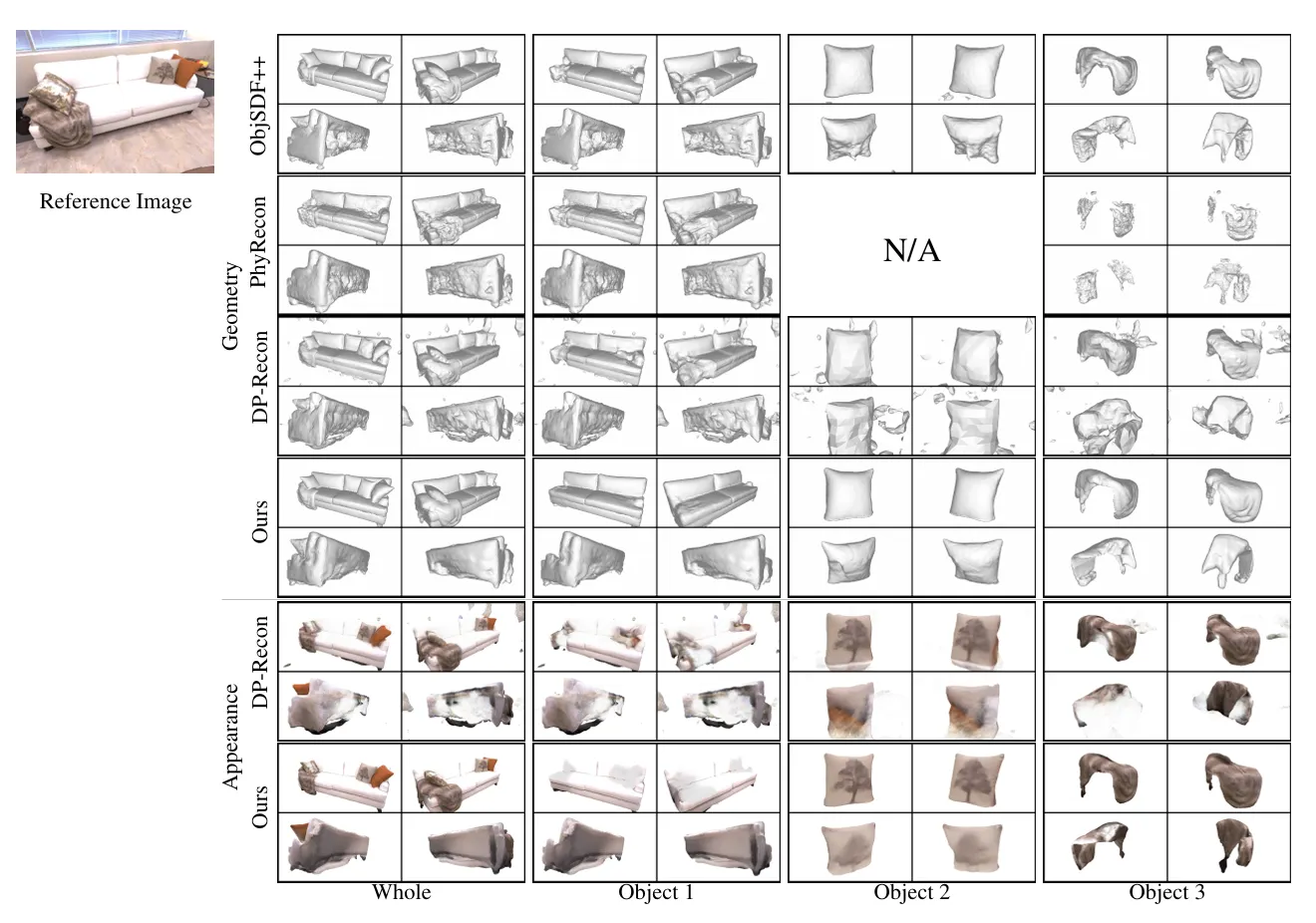
2.3. PhyRecon: Physically Plausible Neural Scene Reconstruction
Introduction
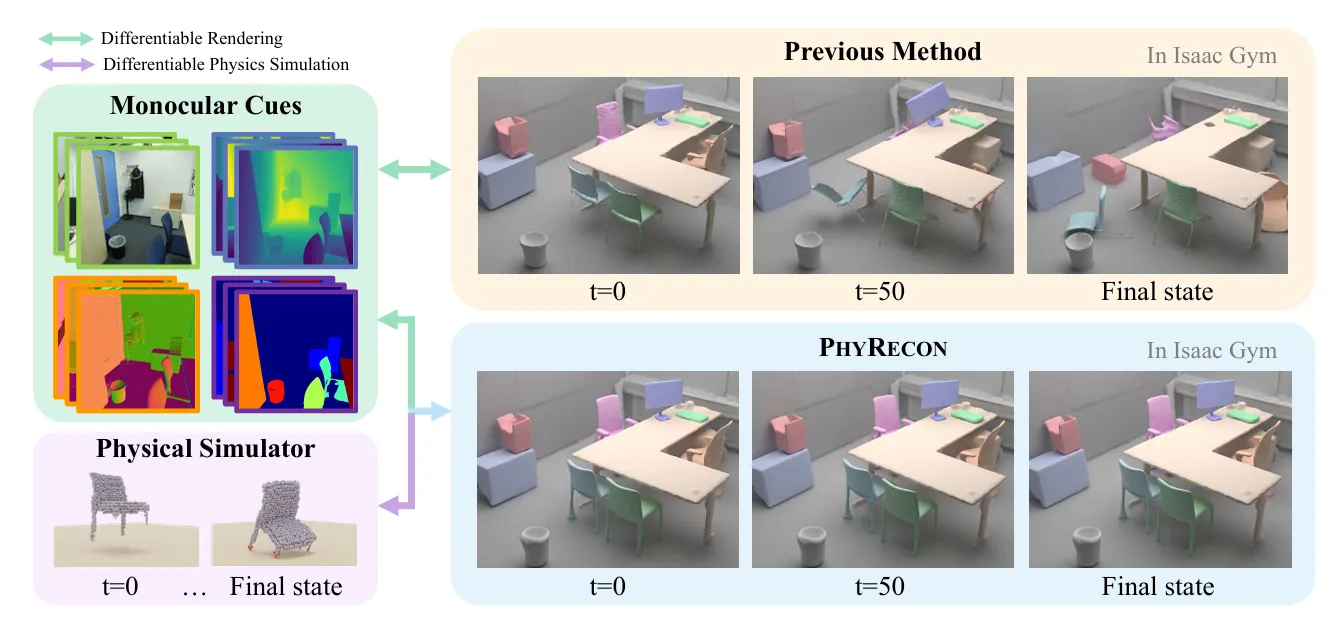
Method
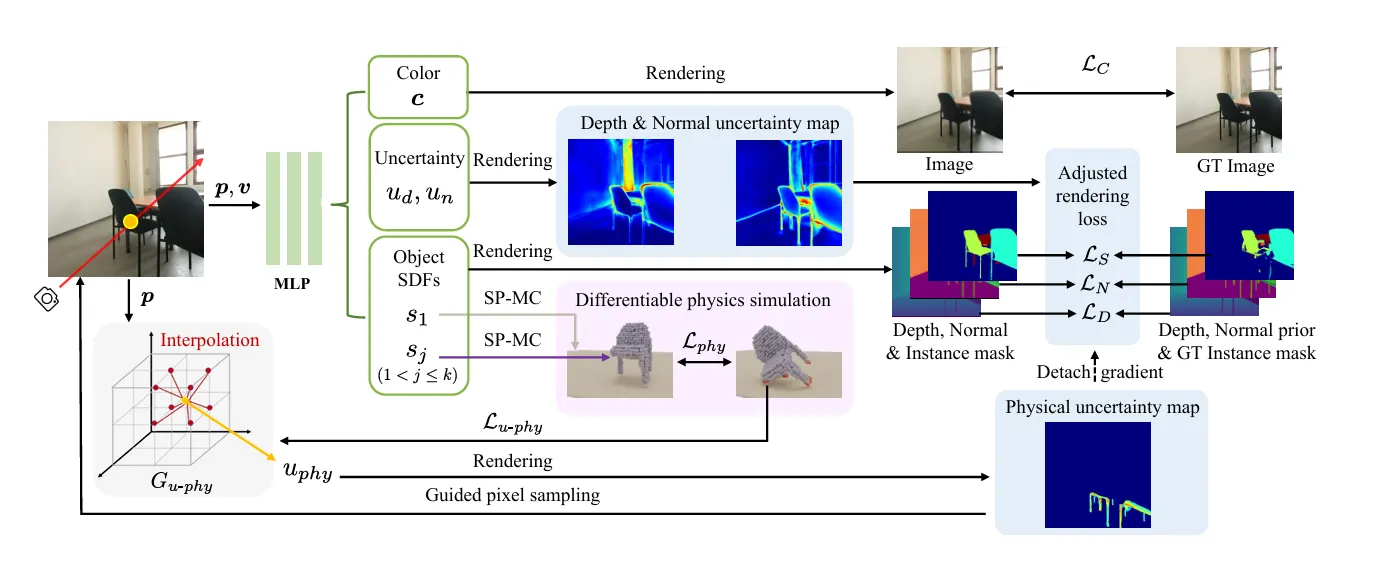
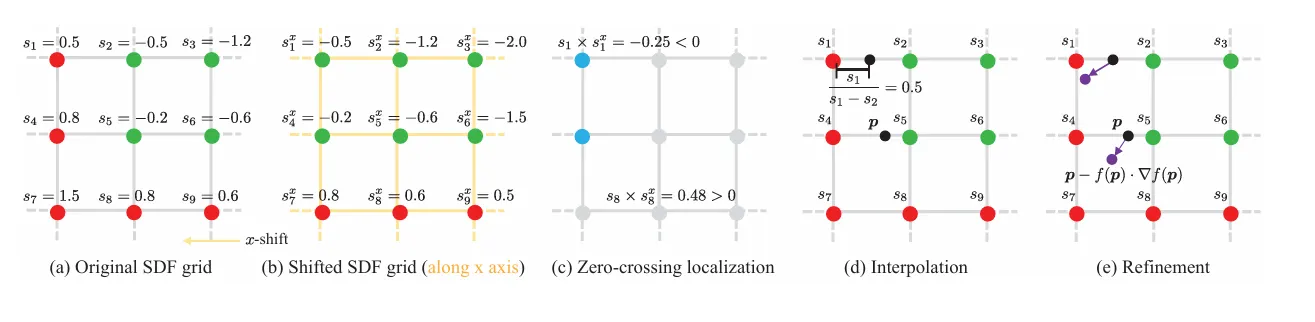
•
Signed Distance Fuction (SDF) 기반의 Implicit Surface를 사용 한 후,
◦
Surface Points Marching Cubes (SP-MC) 를 통해 물리 시뮬레이션에 사용될 수 있는 명시적 형태로의 전환이 가능해짐
•
물체를 입자 집합으로 모델링하여 물리적 상호작용을 시뮬레이션
◦
물체 표면의 접촉점을 기반으로 physical loss를 계산
•
Joint Uncertainty Modeling
◦
Rendering Uncertainty: monocular depth/normal 추론의 불확실성을 고려
◦
Physical Uncertainty: 시뮬레이션 중 물리적으로 불안정한 영역을 파악
◦
두 가지 불확실성을 통해 렌더링 손실 및 픽셀 샘플링을 동적으로 조절
•
Physics-guided Pixel Sampling
◦
물리적으로 불안정한 영역(예: 얇은 구조물)을 우선적으로 학습하도록 픽셀 선택 확률 조정
Experiemts


Limitations
•
입력 이미지가 부족한 영역에서 불안정한 형상이 생성될 수 있음
•
연결되지 않은 객체들이 안정적으로 인식되는 문제 발생 → 향후 topological regularization 필요
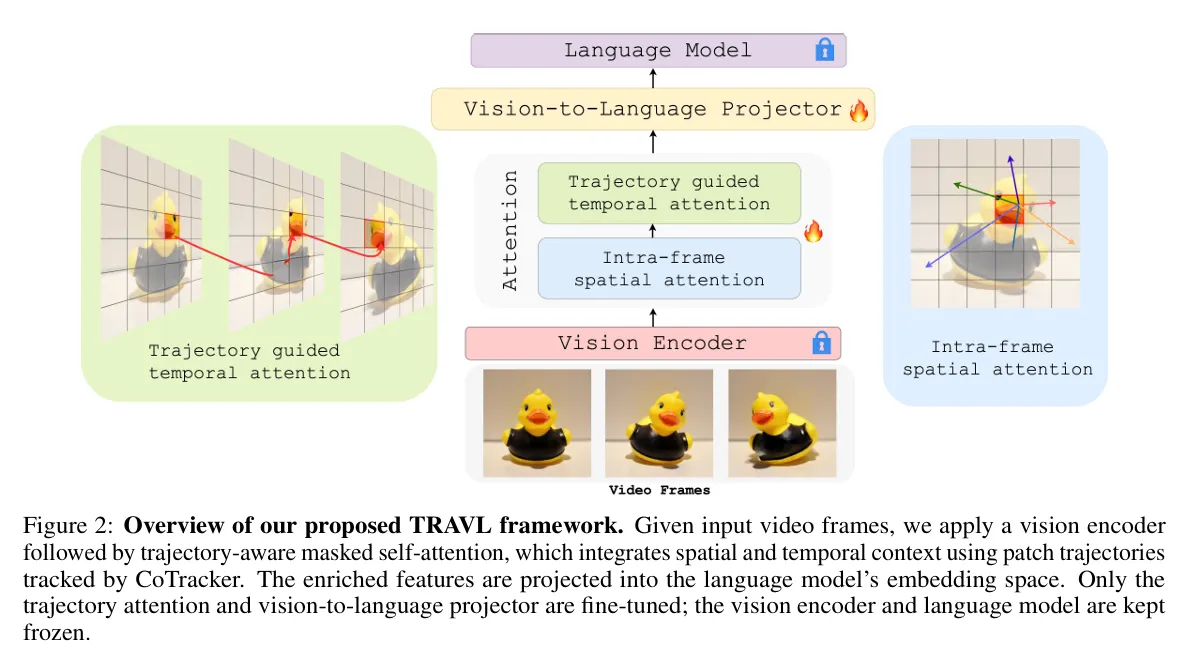
2.5. TRAVL: A RECIPE FOR MAKING VIDEO-LANGUAGE MODELS BETTER JUDGES OF PHYSICS IMPLAUSIBILITY
Introduction
물리 법칙을 위반하는 영상을 더 잘 식별할 수 있도록 훈련하는 방법론 TRAVL 과 평가용 벤치마크 데이터셋을 제안하는 논문
•
최신 영상 생성 모델은 시각적으로는 정교하지만 종종 물리 법칙을 위반하는 결과(예: 물체 부유, 순간 이동)를 생성함.
•
기존 평가 지표(FVD, CLIPSIM)는 물리적 타당성(physical plausibility)보다는 시각적 유사성에 집중함.
•
본 논문은 VLMs가 물리적 타당성 판단자(judge)로 활용 가능한지 탐색하고, 기존 VLM들이 물리 위반을 잘 탐지하지 못함을 지적.
•
이를 해결하기 위해 TRAVL을 도입함: 물체의 궤적(trajectory)을 고려하는 attention 모듈을 통해 물리 이해를 향상시킴.
Related Work
•
Trajectory 기반 모델링
기존 연구에서는 궤적 정보를 활용하여 동작 인식, 영상 편집 등에서 성능 향상
◦
물리 이해를 위한 VLM 개선에 궤적 정보를 사용하는 연구는 드묾
Method
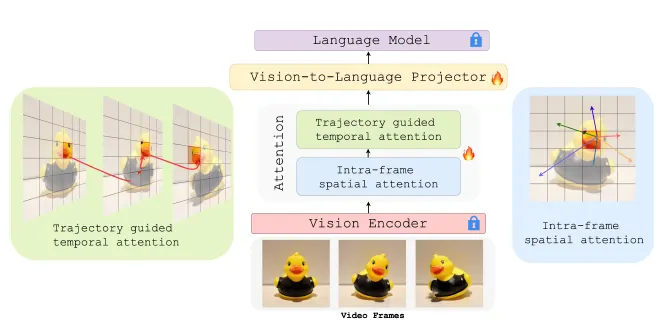
•
TRAVL
◦
Intra-frame Spatial Attention: 각 프레임 내에서 구조적 이상(크기 변화, 변형 등)을 포착.
◦
Trajectory-guided Temporal Attention: CoTracker를 이용해 추출한 물체 궤적에 따라 시간 간 attention을 제한.
◦
이 구조는 물리 위반 (e.g., teleportation, duplication) 탐지를 강화함

Experiemts
•
TRAVL이 적용된 모델은 기존 SFT 모델보다 물리 위반 감지 능력이 우수함.
◦
LLaVA-NeXT 모델의 경우, implausible 영상에 대해 Human 평가 기준에서 SFT 대비 18.7% 성능 향상.
•
Ablation 실험에서 공간 attention과 시간 attention이 상호보완적임을 확인.
Limitations
•
학습 데이터의 다양성과 규모가 제한적이며, 긴 시퀀스를 처리하기 위한 메모리 효율적 구조가 필요함.
•
CoTracker 기반 궤적 추출의 계산 비용 문제도 존재.
Discussion
•
Scene Graph에 물리적이거나 기능적인 관계를 포함하는 경우(1.1, 1.2, 1.4) 와 수식으로 Agent 형태로 객체를 분리하거나 물리적으로 타당하게 만드는(2.1) 경우가 있는 것으로 보임
◦
그렇다면 Scene Graph가 반드시 필요한 이유는 무엇일까?
▪
실시간 로봇 운용에서는 아무래도 Scene Graph가 필요한 것으로 보임
•
물리적인 것을 이해하는 VLM 등에 관한 논문은 최근 벤치마크부터 만들어가는 과정으로 보이고, 유명 대기업의 선행연구 논문들이 많이 보이는 추세로 보임 (구글 딥마인드, 메타 등)
◦
벤치마크 데이터셋은 계속해서 나오는 상황이고, 여러 학회에서 계속 다뤄지지 않을까도 생각이 됨
▪
특히, 최근 나온 벤치마크 데이테셋들의 출시 일자는 9월 ~ 10월이라 빠르게 가져가면 이점이 있을 수도 있을걸로 보임
우리가 가져온 논문 중에
•
중요하다고 생각되거나,
•
재밌다고 생각되거나,
•
우리가 낼 학회에 충분히 도전해볼 수 있겠다 싶은 논문 선택하기
문제 정의 및 참고할 데이터셋 서치
Limitations
•
당연하게도 전부를 알아온 것은 아니라는 것.
Future Work
•
도전해보고 싶은 문제정의가 잘 됐다면,
•
도전해보고 싶은 문제가 없다면,