Objectives
이 글은 VLM/LLM에 대한 포괄적인 내용을 기반으로 기본기를 다잡고자 하는 마음으로 썼다.
VLM 전반에 대한 기본적인 내용을 공부함으로써 VLM 리서처로서 파인튜닝에 관련된 기본 지식을 얻는 것이 이번 글의 목적이다.
1. VLM Architectures

VLM 아키텍처는 3가지 핵심 설계로 정의된다:
1.
Fusion Strategy: Early / Intermediate / Late
2.
Fusion Mechanism: Linear / Q-Former / Perceiver / Cross-Attention
3.
Overall Pattern: Encoder-Only / Encoder-Decoder / Decoder-Only
현재 트렌드는 Intermediate Fusion + Frozen Pretrained Models + Efficient Adapters 조합이 지배적이며, 이는 비용 효율성과 성능의 최적 균형을 찾는 것을 목표로 한다.
1.1. Core Components
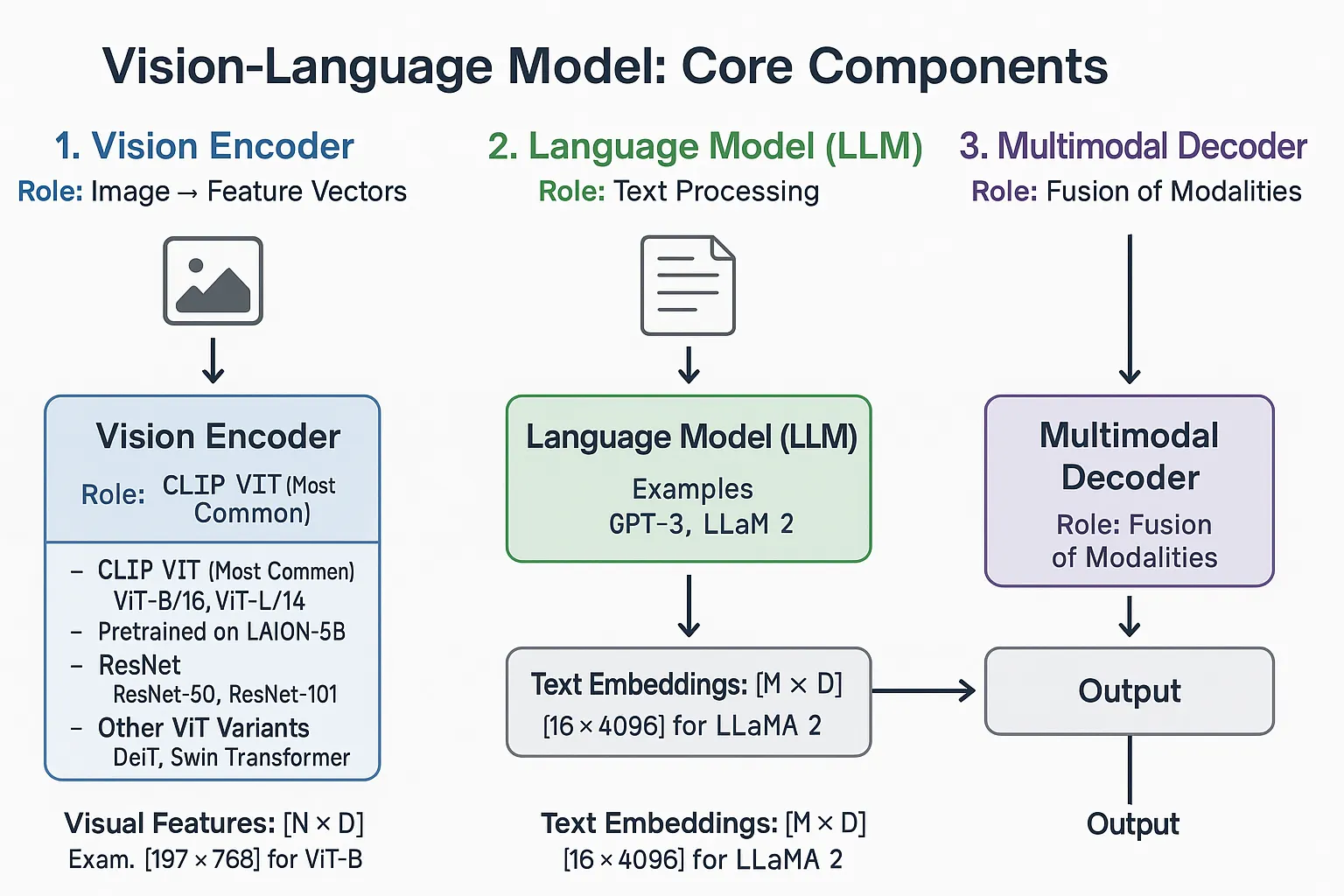
VLM은 일반적으로 3가지 핵심 요소로 구성된다:
•
Vision Encoder
◦
역할: 이미지를 특징 벡터(Embedding)로 변환
◦
주요 아키텍처:
▪
CLIP ViT (Vision Transformer): 가장 널리 사용
▪
ResNet: CNN 기반 인코더
•
LM (Language Model)
◦
역할: 텍스트 처리 및 생성
◦
주요 선택지:
▪
LLaMA/Vicuna: 오픈소스 LLM
▪
GPT 계열: Decoder-only 아키텍처
▪
T5/BERT: Encoder-decoder 아키텍처
•
Modality Fusion / Alignment Module
◦
역할: 비전과 언어 간 간극 연결
◦
주요 메커니즘: (아래에서 상세 설명)
1.2. 모달리티 융합 전략 (Fusion Strategies)
1.2.1 Early Fusion (조기 융합)
개념: 이미지와 텍스트를 처리 초기에 결합
[Image Features] ⊕ [Text Features] → Unified Model → Output
Plain Text
복사
특징:
•
입력 레벨 또는 초기 레이어에서 융합
•
단순 concatenation 또는 공유 임베딩 공간으로 투영
•
모달리티 간 긴밀한 상호작용
장점:
•
모달리티 간 저수준 특징 상호작용 가능
•
단순하고 구현이 쉬움
•
긴밀하게 연결된 데이터에 효과적
단점:
•
각 모달리티의 독립적 표현 학습 제한
•
차원의 저주 문제
대표 모델:
•
Chameleon: Token-based early-fusion
•
VisualBERT: BERT에 이미지 임베딩 직접 결합
1.2.2 Late Fusion (후기 융합 / Decision-level Fusion)
개념: 각 모달리티를 독립적으로 처리 후 최종 출력 단계에서 결합
Image → Vision Model → Visual Features ──┐
├→ Fusion → Output
Text → Language Model → Text Features ──┘
Plain Text
복사
특징:
•
각 모달리티가 깊은 레이어까지 독립적 처리
•
최종 예측/결정 단계에서만 통합
•
대표적으로 joint embedding space 학습
장점:
•
각 모달리티의 전문화된 처리 가능
•
사전학습된 모델 활용 용이
•
유연성과 모듈성
단점:
•
모달리티 간 상호작용 제한적
•
복잡한 cross-modal reasoning에 불리
대표 모델:
•
CLIP: Contrastive learning으로 joint embedding 학습
•
ALIGN: 웹 규모 noisy 데이터로 학습
1.2.3 Intermediate Fusion (중간 융합)
개념: 각 모달리티를 일부 독립적으로 처리한 후 중간 레이어에서 융합
Image → Vision Layers → Visual Features ──┐
├→ Cross-Attention → Fused Layers → Output
Text → Language Layers → Text Features ──┘
Plain Text
복사
특징:
•
중간 단계에서 Cross-Attention 메커니즘 사용
•
각 모달리티가 중간 수준의 이해 발전 후 통합
•
복잡성과 성능의 균형
장점:
•
저수준과 고수준 특징 모두 활용
•
효과적인 cross-modal reasoning
•
Early와 Late fusion의 장점 결합
단점:
•
아키텍처 복잡도 증가
•
학습 난이도 상승
대표 모델:
•
Flamingo: Perceiver Resampler + Gated Cross-Attention
•
BLIP-2: Q-Former로 중간 정렬
•
VisualGPT: Cross-attention layers
•
LXMERT: Cross-modality encoder
1.3. 전문화된 Fusion 메커니즘
1.3.1 Linear Projection / MLP Adapters - LLAVA
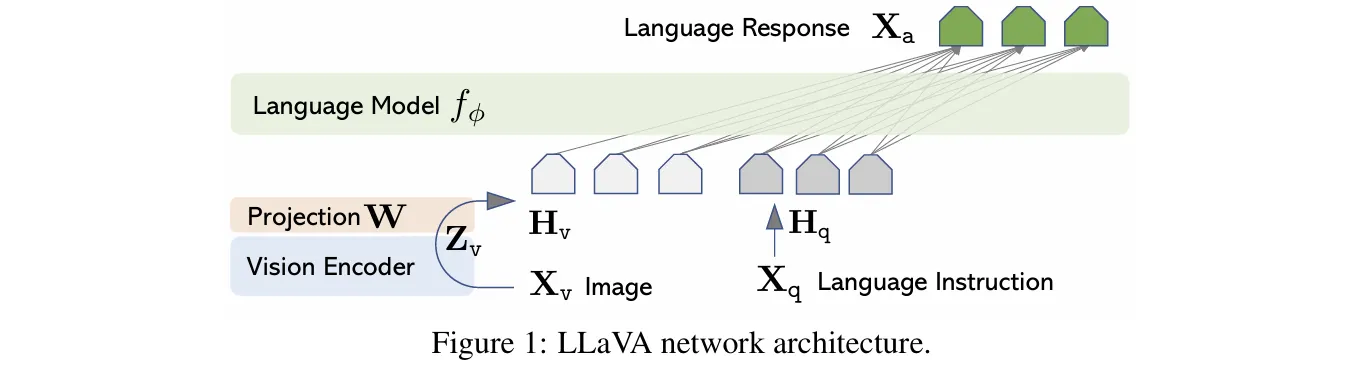
가장 단순한 방식
# 개념적 구조
vision_features = vision_encoder(image) # [B, 257, 768]
text_embeddings = projection_layer(vision_features) # [B, 257, 4096]
llm_output = language_model(text_embeddings)
Python
복사
특징:
•
Vision encoder 출력을 LLM 입력 차원에 맞게 변환
•
1-2개의 fully connected layers
•
파라미터 효율적
대표 모델:
•
LLaVA: CLIP ViT-L + Linear Projection + Vicuna
◦
Stage 1: Projection만 학습 (alignment)
◦
Stage 2: End-to-end 파인튜닝
장점:
•
구현 간단
•
계산 비용 낮음
•
사전학습된 모델 활용 용이
단점:
•
표현력 제한적
•
복잡한 시각-언어 정렬에 한계
1.3.2 Q-Former (Querying Transformer) - BLIP-2
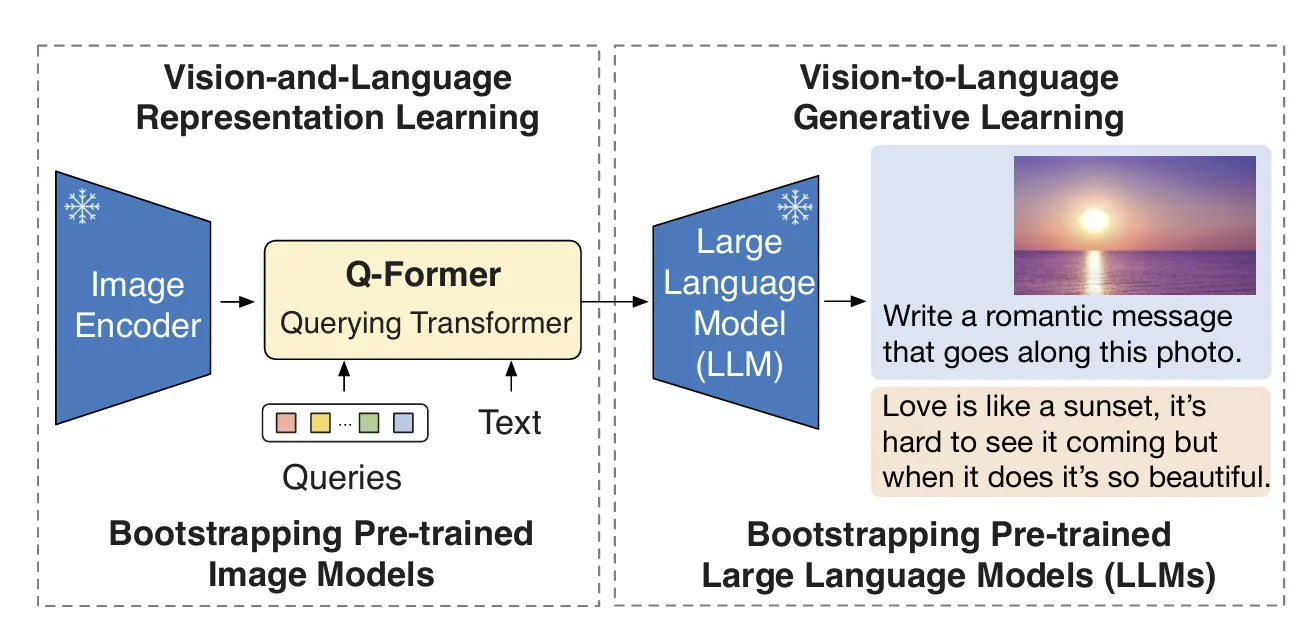
아키텍처:
Frozen Image Encoder → Visual Features
↓
Q-Former (188M params)
├─ Image Transformer (32 learnable queries)
│ └─ Self-Attention + Cross-Attention
└─ Text Transformer (Encoder/Decoder)
↓
Frozen LLM → Output
Plain Text
복사
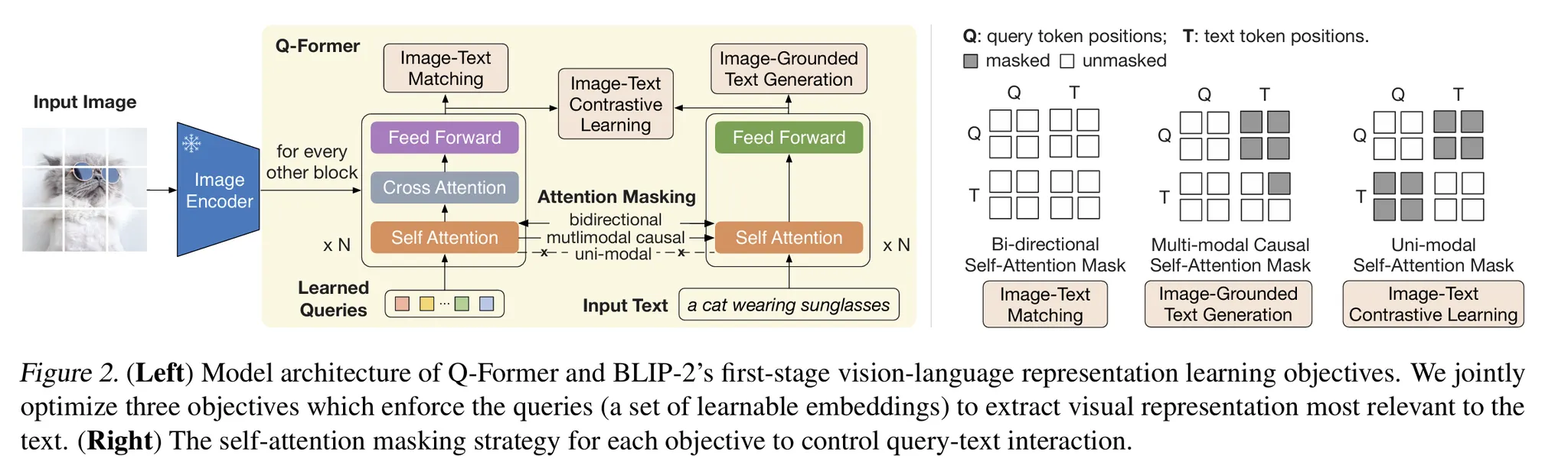
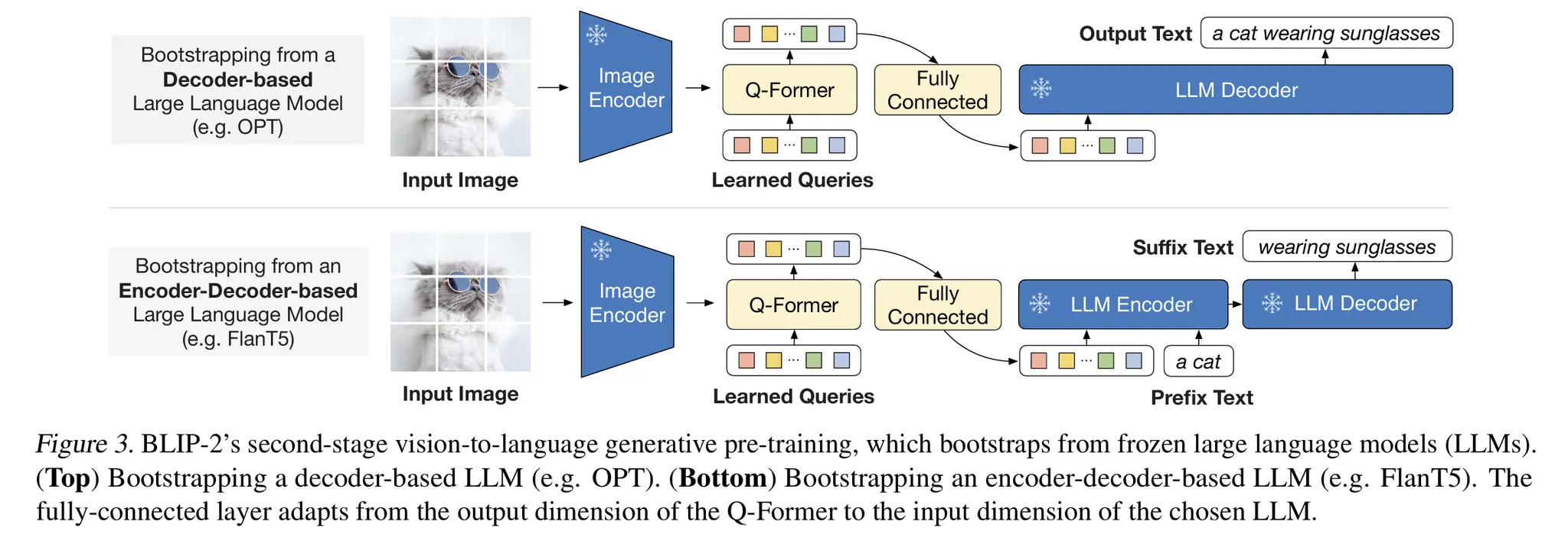
핵심 메커니즘:
1.
Learnable Query Embeddings (32개, 768-dim):
•
이미지에서 가장 관련성 높은 시각 정보 추출
•
Self-attention으로 쿼리 간 상호작용
•
Cross-attention으로 frozen 이미지 특징과 상호작용
2.
2-Stage Pre-training:
•
Stage 1 - Vision-Language Representation Learning:
◦
ITC (Image-Text Contrastive): 이미지-텍스트 정렬
◦
ITG (Image-grounded Text Generation): 이미지 조건부 텍스트 생성
◦
ITM (Image-Text Matching): 매칭 예측
•
Stage 2 - Vision-to-Language Generative Learning:
◦
Frozen LLM에 연결
◦
시각 정보를 언어 생성으로 변환
장점:
•
고정된 수의 visual token 출력 (이미지 해상도 무관)
•
계산 효율성 (188M vs 수십억 파라미터 LLM)
•
텍스트와 가장 관련된 시각 정보만 추출
성능:
•
Flamingo 대비 8.7% 향상 (zero-shot VQA)
•
54배 적은 학습 가능 파라미터
1.3.3 Perceiver Resampler - Flamingo
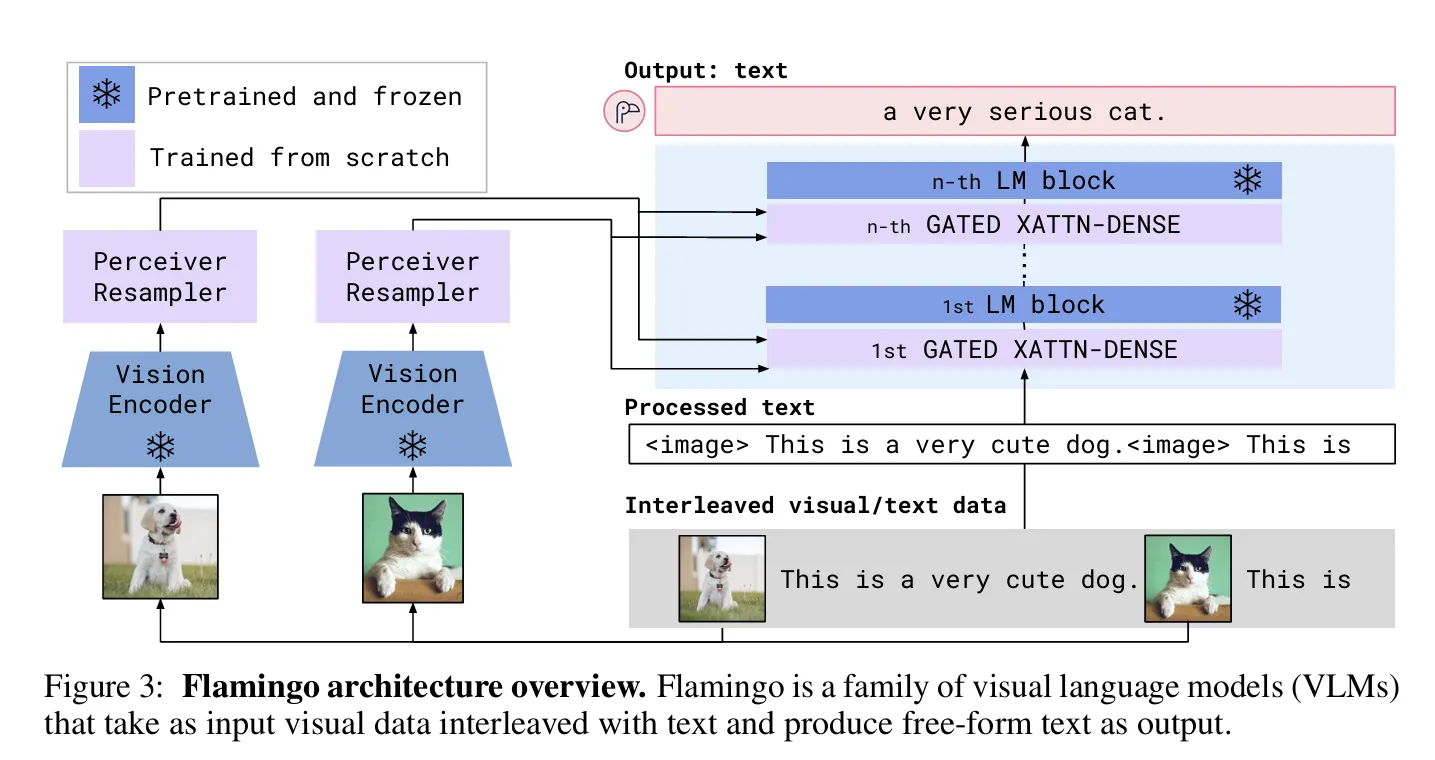
아키텍처:
Variable-size Image/Video Features (from frozen Vision Encoder)
↓
Perceiver Resampler
├─ Fixed Latent Queries (64개)
└─ Cross-Attention to Visual Features
↓
64 Visual Tokens (fixed size)
↓
Gated Cross-Attention Layers
(inserted into frozen LLM layers)
↓
LLM Output
Plain Text
복사
핵심 메커니즘:
1.
Perceiver Architecture:
•
사전정의된 latent input queries
•
가변 크기 feature map → 고정 크기 visual token 변환
•
Transformer module에 cross-attend
2.
Gated Cross-Attention:
•
LLM의 기존 레이어 사이에 삽입
•
Tanh gating으로 시각 정보 주입 제어
•
언어 모델 성능 보존
장점:
•
계산 복잡도 대폭 감소 (large feature maps → few tokens)
•
비디오 프레임 처리 효율적
•
Few-shot learning 능력 탁월
특징:
•
Vision encoder와 LLM 모두 frozen
•
오직 Perceiver Resampler와 gated cross-attention만 학습
•
Interleaved image-text 시퀀스 처리 가능
1.3.4 Cross-Attention Mechanisms
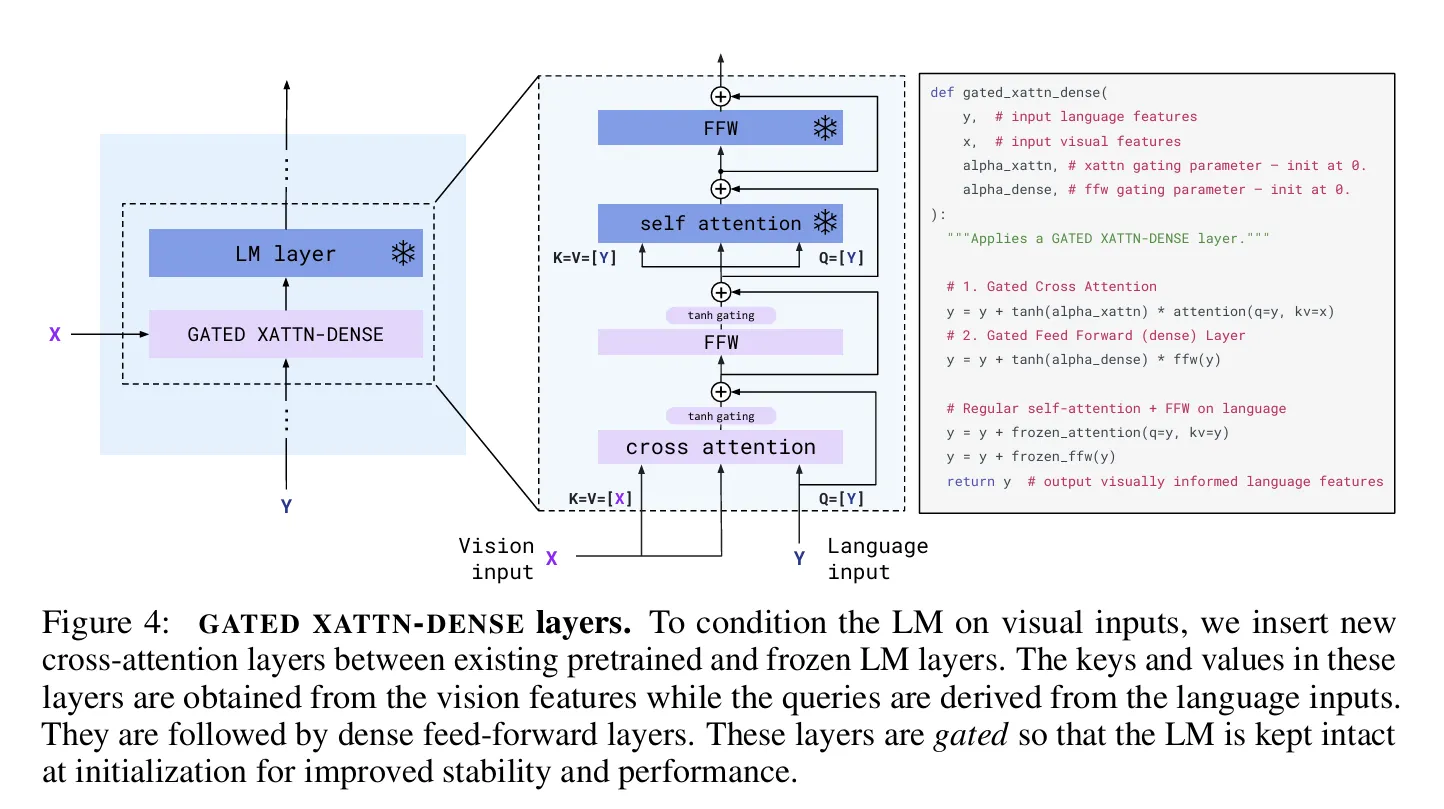
•
여러 레이어에 통합되는 방식
◦
Cross-Attention 이 언어 모델의 여러 레이어에 통합되어 텍스트와 시각 정보 간의 깊은 상호작용을 가능하게 함
메커니즘:
# 개념적 구조
for layer in language_model.layers:
# Standard self-attention on text
text_features = layer.self_attention(text_features)
# Cross-attention: text queries, vision keys/values
attended_features = layer.cross_attention(
query=text_features,
key=vision_features,
value=vision_features
)
# Gating mechanism (optional)
output = tanh_gate * attended_features + text_features
Python
복사
삽입 위치:
•
모든 레이어: 강한 시각-언어 통합 (VisualGPT)
•
매 N번째 블록: 계산 효율성과 성능 균형 (Flamingo - 매 4번째)
•
특정 레이어: 전략적 배치
대표 모델:
•
Flamingo: Gated cross-attention (every 4th layer)
•
VisualGPT: 모든 decoder 레이어
•
FIBER: Vision + Language 백본 모두에 삽입
장점:
•
풍부한 cross-modal interaction
•
유연한 시각 정보 주입
•
사전학습 LLM 활용 가능
단점:
•
계산 비용 증가
•
LLM frozen 시 제한적 효과
1.4. 전체 아키텍처 패턴 비교
다양한 아키텍쳐 패턴들 Vision Language Models: A Survey of 26K Papers
1.4.1 Encoder-Only Models
구조: Dual Encoder Architecture
Image → Vision Encoder → Visual Embedding ──┐
├→ Contrastive Loss
Text → Text Encoder → Text Embedding ──┘
Plain Text
복사
목적: Joint embedding space 학습
대표 모델:
•
CLIP: Image & Text 동시 인코딩, contrastive learning
•
ALIGN: Noisy web data로 학습
•
SigLIP: Sigmoid loss 변형
태스크:
•
Zero-shot 이미지 분류
•
Image-text retrieval
•
Image segmentation (CLIPSeg)
특징:
•
Late fusion
•
양방향 검색 가능
•
효율적 inference
1.4.2 Encoder-Decoder Models
구조: Unified Architecture
Image → Vision Encoder ──┐
├→ Fusion Module → Decoder → Generated Text
Text → Text Encoder ──┘
Plain Text
복사
대표 모델:
•
BLIP: Multimodal Mixture of Encoder-Decoder (MED)
◦
ITC (Image-Text Contrastive)
◦
ITM (Image-Text Matching)
◦
ITG (Image-grounded Text Generation)
BLIP MED 구조:
•
Unimodal encoder: 독립적 이미지/텍스트 처리
•
Image-grounded text encoder: Cross-attention으로 융합
•
Image-grounded text decoder: Caption/VQA 생성
장점:
•
Understanding & Generation 통합
•
다양한 downstream task 지원
•
Captioning, VQA, Retrieval 모두 가능
1.4.3 Decoder-Only Models (with Vision Prefix)
구조: Frozen LLM + Vision Adapter
Image → Vision Encoder → Adapter/Q-Former → Visual Tokens
↓
[Visual Tokens] + [Text Tokens]
↓
Frozen/Fine-tuned LLM
↓
Generated Text
Plain Text
복사
핵심 아이디어: 이미지를 LLM의 "prefix"로 취급
대표 모델:
1. Frozen PrefixLM:
•
Frozen: Vision encoder만 학습, LLM frozen
•
ClipCap: CLIP 임베딩 → GPT-2
•
제한된 aligned data로 학습 가능
2. Trainable PrefixLM:
•
SimVLM: Encoder-decoder unified architecture
•
VirTex: Image patch sequence as prefix
3. Advanced Variants:
•
LLaVA: Simple linear projection
•
BLIP-2: Q-Former (frozen both)
•
Flamingo: Perceiver Resampler + Gated Cross-Attention
•
InstructBLIP: Q-Former + Instruction tuning
장점:
•
강력한 LLM 능력 활용
•
Few-shot learning
•
Conversational AI 적합
•
Instruction following
1.4.4 Encoder-Free Models
최신 트렌드: Vision Encoder 없이 직접 처리
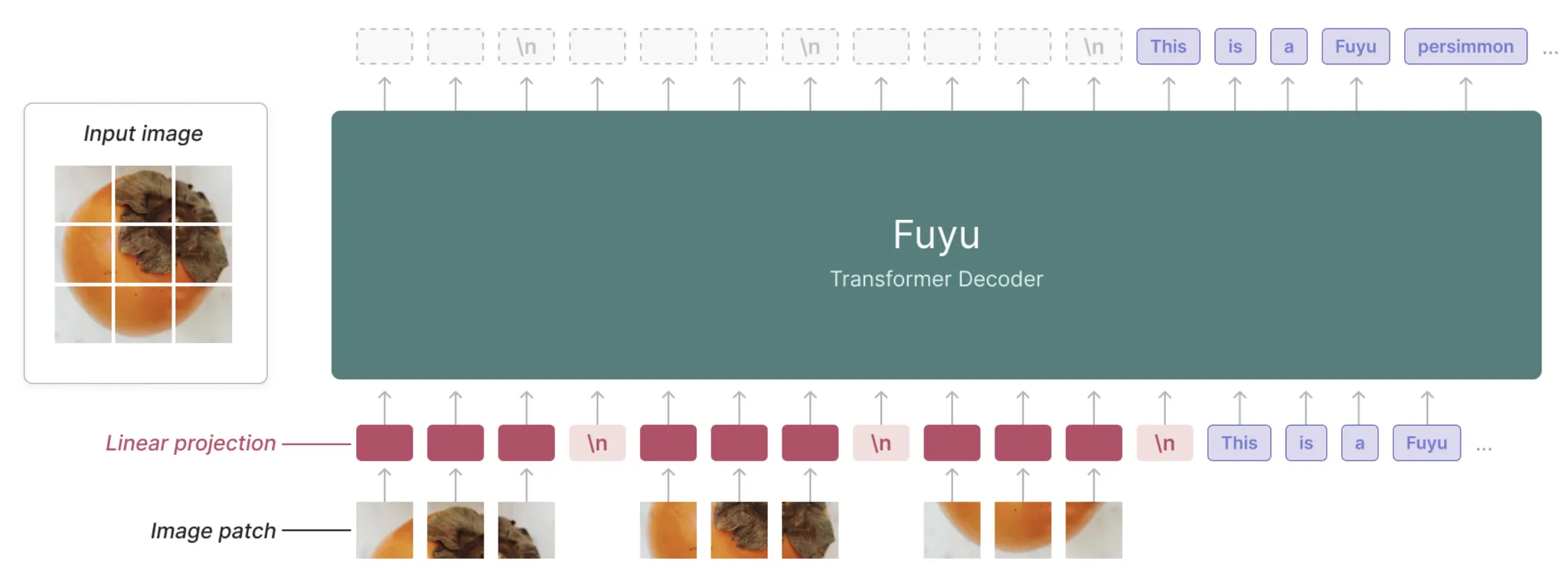
구조:
Image Patches → Tokenization → Unified Decoder → Output
Text Tokens → Tokenization → (same stream)
# e.g. FUYU
Image
→ Patchify (예: 16x16 패치 단위로 잘라서)
→ Linear Projection (패치를 embedding space로 Projection)
→ Position Embedding 추가
→ Transformer(LM)의 입력 토큰 시퀀스로 바로 투입
Plain Text
복사
대표 모델:
•
Fuyu-8B: Decoder-only, encoder 없음
•
EVE: Encoder-free VLM
•
Chameleon: Early-fusion unified architecture
장점:
•
아키텍처 단순화
•
End-to-end 학습
•
Image-text 동등 취급
단점:
•
더 많은 학습 데이터 필요
•
사전학습 vision model 활용 불가
1.5. 주요 VLM 아키텍처 비교표
모델 | Vision Encoder | Fusion Strategy | Language Model | 학습 방식 |
CLIP | ViT/ResNet | Late (Contrastive) | Text Encoder | Both frozen after PT |
LLaVA | CLIP ViT | Intermediate (Linear) | Vicuna (LLaMA) | Linear → E2E FT |
BLIP-2 | ViT-L | Intermediate (Q-Former) | OPT/FLAN-T5 | Both frozen, Q-Former trained |
Flamingo | NFNet | Intermediate (Perceiver) | Chinchilla | Both frozen, Resampler trained |
InstructBLIP | ViT-L | Intermediate (Q-Former) | Vicuna/FLAN-T5 | Instruction tuning |
VisualBERT | Faster R-CNN | Early (Concat) | BERT | E2E Fine-tuning |
LXMERT | Faster R-CNN | Intermediate (Cross-Enc) | Custom | Cross-modal encoder |
FUYU | Vision Transformer (Perceiver Resampler-free) | No explicit fusion module (Unified Transformer) | GPT-style LM (8B) | End-to-End Training |
2. An Overview of LLM/VLM Training
2.1. Training Workflows
2.1.1. For LLMs
simply put, Pretraining → SFT → Preference Optimization → RLHF → (Distillation)
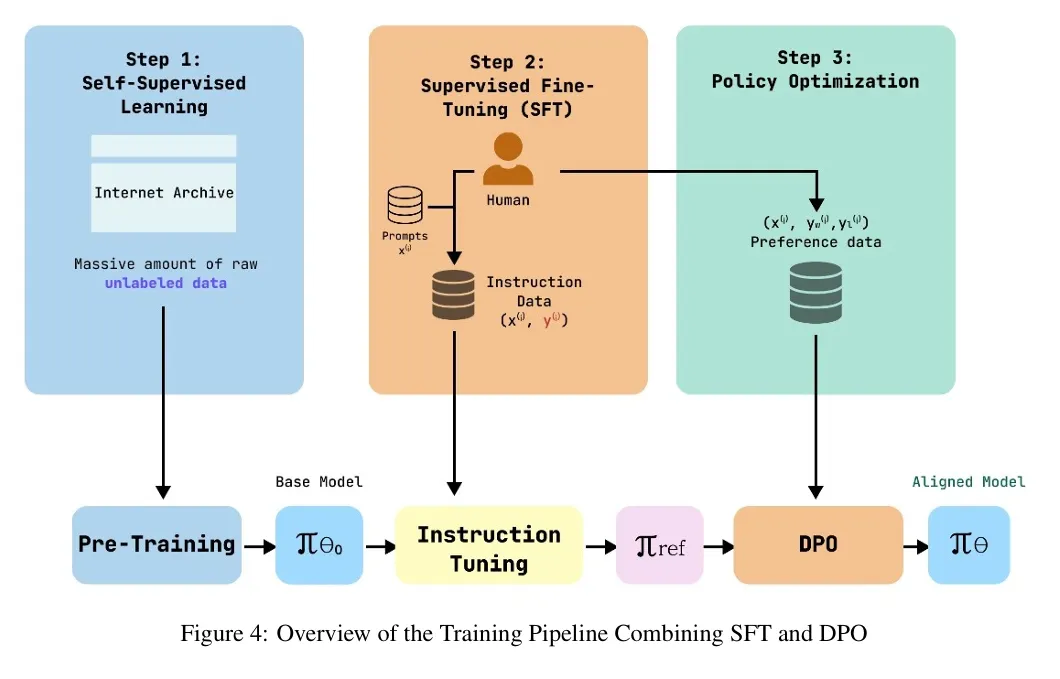
•
Pretraining
◦
인터넷 텍스트를 대규모로 수집
◦
Next Token Prediction(NTP)
◦
언어 구조/지식/논리 패턴을 학습
◦
복잡한 reasoning 능력의 기반이 이 단계에서 형성됨
•
Fine-tuning
◦
특정 태스크(예: 요약, 번역, QA)에 잘 대응하거나 필요한 지식을 주입/제거하기 위해서 지도학습
◦
사람이 작성한 고품질 data 교육
◦
모델이 ‘사용자가 원하는 형태’의 응답을 생성하기 시작함
•
Preference Optimization
◦
SFT가 끝나면, 모델이 사용자가 “더 선호하는 답변”을 내놓도록 조정
◦
별도의 정책 네트워크 없이, pairwise comparison 기반으로 학습
•
RLHF (Reinforcement Learning from Human Feedback)
◦
인간 피드백을 보상 모델로 학습
◦
정책경사(PPO 등)를 이용해 ‘선호도’를 강화
◦
모델을 "안전하고 유용하며 친절하게" 만드는 핵심 단계
◦
최근에는 비용 때문에 DPO로 대체되는 경향 있음
2.1.2. For VLM
•
Vision (Vision Encoder Pretraining)
◦
이미지를 벡터로 변환하는 Vision Encoder 학습
▪
예: ViT, CLIP-Vision, SAM-Backbone, SigLIP 등
◦
self-supervised(자기지도) 방식 + contrastive learning
◦
이미지의 구조·패턴·Semantic 정보를 압축하는 단계
•
Alignment (Image-Text Alignment)
◦
이미지 embedding 텍스트 embedding 을 같은 의미 공간으로 정렬
텍스트 embedding 을 같은 의미 공간으로 정렬◦
방법:
▪
CLIP-style contrastive loss
▪
Q-Former (BLIP-2)
▪
Perceiver-resampler (Gemini)
▪
Projector MLP (LLaVA)
•
Fusion
Alignment가 끝나면 LLM과 본격적으로 결합.
◦
Multimodal Instruction Tuning
◦
이미지 기반 QA, Caption, OCR, reasoning 데이터로 SFT
•
하지만, 모델마다 몇 단계를 생략하거나 합치거나 대체하는 경우가 많음
◦
이미지 + 텍스트를 함께 받아 따라 말하는 능력 형성
▪
예를 들어 다음과 같은 방식이 등장:
•
Early fusion (Chameleon)
•
Late fusion (LLaVA)
•
Unified token fusion (Qwen2.5-VL)
◦
Unified Transformer를 쓰는 FUYU, Chameleon 모델이 대표적
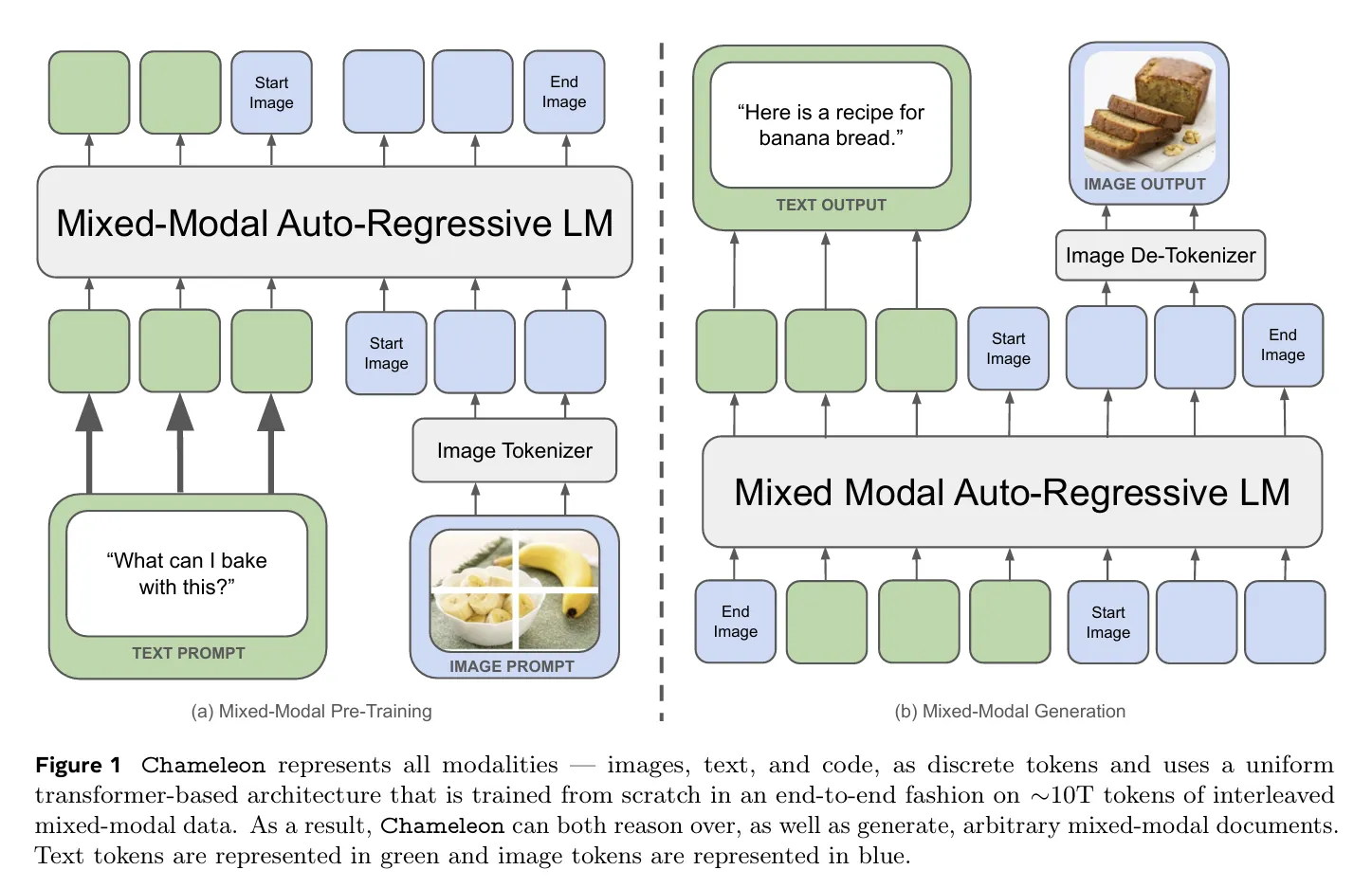
Chameleon
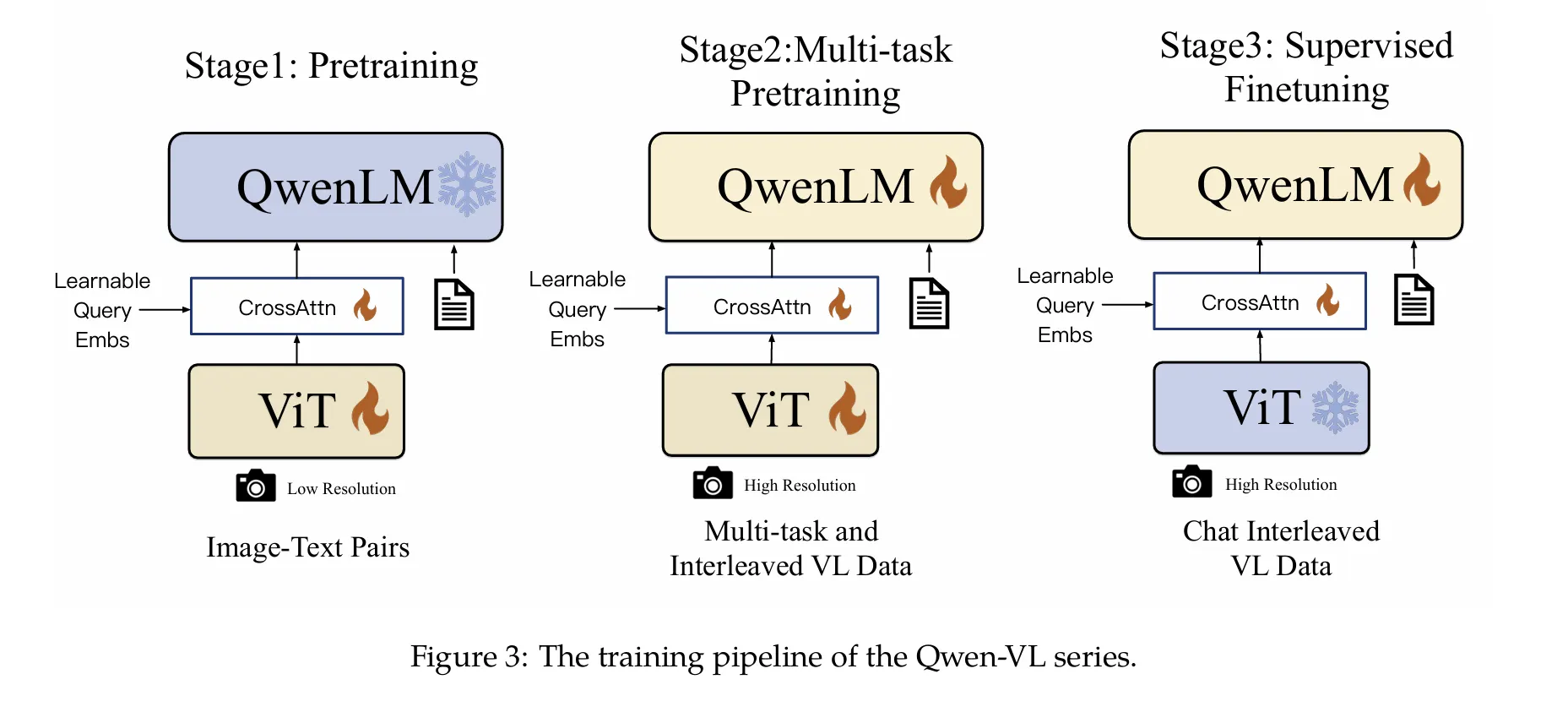
QWEN-VL 예시
2.2. Training Paradigms
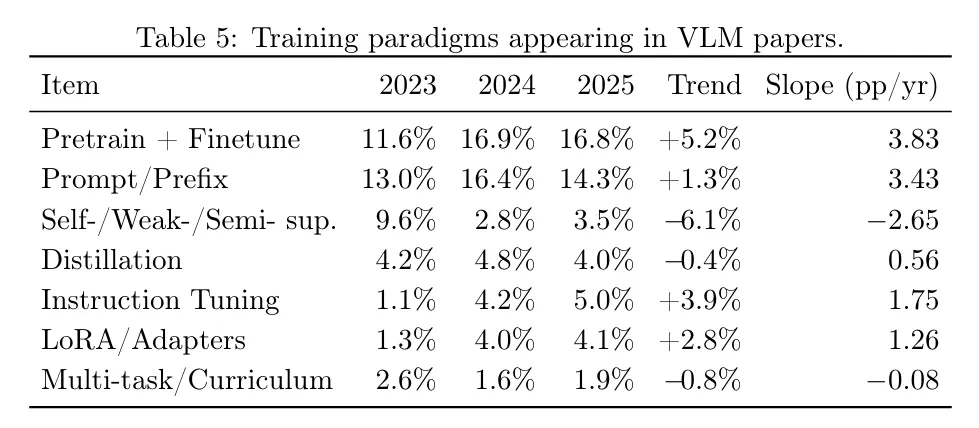
최근 VLM 리서치에서 사용되는 트레이닝 페러다임을 분석한 논문, Vision Language Models: A Survey of 26K Papers
1.
Pretrain + Finetune
Pretraining(사전학습)은 모델이 세상에 대한 기본적 지식과 패턴을 배우는 첫 단계이다.
LLM은 거대한 텍스트 코퍼스를 통해 언어의 문법, 상식, 추론 패턴을 익히고,
VLM은 이미지–텍스트 쌍이나 대규모 시각 데이터로부터 시각적 표현을 학습한다.
이후 Finetuning(미세조정)을 통해 특정 작업(예: 의료 진단, 이미지 캡션, 코드 생성)에 맞게 모델이 조정된다.
이 단계에서는 전체 모델을 업데이트하거나, 일부 모듈만 조정하거나, Adapter/LoRA처럼 가벼운 기법을 사용할 수도 있다.
핵심 포인트:
•
Pretraining → 일반적 지식
•
Finetuning → 특정 과제 능력 강화
2.
Prompt / Prefix
Prompt Tuning은 모델 파라미터를 그대로 유지하고, 입력 앞에 붙이는 prompt embedding만 학습하는 방식이다.
Prefix Tuning은 Prompt Tuning과 유사하지만, 모델의 내부 attention 계산에 영향을 주는 prefix key/value 벡터를 학습한다.
이 방식의 장점은 다음과 같다.
•
전체 모델을 건드리지 않아서 안정적임
•
학습해야 할 파라미터가 매우 적어 비용이 낮음
•
도메인별 프롬프트만 따로 저장해 task-switching이 쉬움
VLM에서는 시각 프롬프트(visual prompt)를 별도로 학습하여 이미지 인코더를 건드리지 않고 새로운 상황에 적응시키기도 한다.
3.
Instruction Tuning
Instruction Tuning은 모델에게 자연어 지시(instruction)를 이해하고 따라 하는 능력을 부여하는 과정이다.
예:
•
“이 이미지를 설명해줘.”
•
“사진 속 사람의 감정을 분석해줘.”
•
“이 코드에서 버그를 찾아줘.”
VLM에서는 이미지+질문 형태의 instruction을 대규모로 제공하며, 모델이 대화형 이해와 멀티모달 reasoning을 배우게 된다.
이 단계는 최근의 LLM/VLM 성능 향상을 주도하고 있으며, 챗봇·도우미·멀티모달 에이전트의 핵심 능력도 대부분 이 단계에서 생긴다.
4.
LoRA / Adapters
LoRA와 Adapter는 전체 모델을 미세조정하지 않고,
중간 모듈에 작은 추가 레이어(adapters)를 삽입하여 학습하는 방식이다.
특징:
•
GPU 메모리 사용량이 매우 적다
•
여러 LoRA를 조합해 다양한 능력을 쌓을 수 있다
•
원본 모델을 그대로 유지하면서 “기능 모듈”을 추가하는 구조
VLM에서는 vision encoder, projection layer, multimodal fusion layer 등 특정 지점에 Adapter를 삽입해 효율적으로 학습시키는 경우가 많다.
5.
Self- / Weak- / Semi-supervision
이 범주는 라벨이 적거나 없어도 모델이 스스로 표현을 학습하는 방식이다.
예:
•
이미지 패치를 재구성하기
•
두 augmented view가 같은 이미지인지 구별하기(contrastive learning)
•
noisy 웹 이미지–텍스트 쌍 활용(CLIP/ALIGN 스타일)
VLM의 vision encoder는 대부분 이런 방식으로 먼저 학습되며,
강력한 시각 표현을 만든 뒤에 이후 멀티모달 학습으로 결합된다.
6.
Distillation
Distillation은 큰 모델(teacher)의 지식을 작은 모델(student)에 압축하는 과정이다.
용도:
•
모델 경량화
•
추론 속도 개선
•
대규모 모델에서 얻은 reasoning 능력을 소형 VLM에 이식
•
멀티모달 bridge layer 정렬에도 사용
최근에는 reasoning distillation(강한 추론 능력을 작고 빠른 모델에 전달)이 활발히 연구되고 있다.
7.
Multi-task / Curriculum
Multi-task Learning은 여러 작업(예: 캡션, VQA, OCR, grounding)을 동시에 학습시키는 방법이며,
Curriculum Learning은 쉬운 작업 → 어려운 작업 순으로 학습을 구조화하는 방식이다.
효과:
•
다양한 능력 간 상호보완
•
더 일반화된 표현 학습
•
어려운 태스크로 가기 전에 기초 reasoning을 안정적으로 학습
최근에는 instruction tuning 데이터셋 안에 자연스럽게 여러 태스크가 섞여 있어,
multi-task 성격의 학습이 기본적으로 포함된 경우가 많다.
3. LLM Trainers in HuggingFace Libarary
3.1. Supervised Fine-Tuning
3.1.1. SFT (Supervised Fine-Tuning)
•
논문: 다양한 SFT 관련 논문들
•
주요 출처:
◦
"FisherSFT: Data-Efficient Supervised Fine-Tuning" arXiv:2505.14826
◦
"How Abilities in Large Language Models are Affected by Supervised Fine-tuning" (ACL 2024)
•
설명: LLM 파인튜닝의 기본이 되는 지도 학습 방법
3.2. Preference Optimization (Alignment Tuning)
3.2.1. DPO (Direct Preference Optimization)
•
논문: "Direct Preference Optimization: Your Language Model is Secretly a Reward Model"
•
저자: Rafael Rafailov et al.
•
•
설명: 명시적인 보상 모델링이나 강화학습 없이 직접 선호도를 최적화하는 방법
•
추가적으로, Online DPO
◦
논문: "Online Direct Preference Optimization with Fast-Slow Chasing"
◦
저자: OFS-DPO 연구팀
◦
◦
설명: 온라인 AI 피드백을 활용한 DPO의 개선 버전
3.2.2. CPO (Contrastive Preference Optimization)
•
논문: "Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation"
•
저자: Haoran Xu, Amr Sharaf et al.
•
•
설명: DPO의 대안으로 제안된 방법으로, 완벽하지 않은 번역 생성을 회피하도록 모델을 학습
3.2.3. KTO (Kahneman-Tversky Optimization)
•
논문: "KTO: Model Alignment as Prospect Theoretic Optimization"
•
저자: Contextual AI 연구팀
•
•
설명: 카너먼-트버스키의 전망 이론을 활용하여 이진 신호(좋음/나쁨)로 학습하는 방법
3.2.4. Nash-MD (Nash Learning from Human Feedback)
•
논문: "Nash Learning from Human Feedback"
•
저자: Rémi Munos, Michal Valko et al.
•
•
설명: 미러 디센트 원리를 기반으로 한 내쉬 균형 학습 접근법
3.2.5. ORPO (Odds Ratio Preference Optimization)
•
논문: "ORPO: Monolithic Preference Optimization without Reference Model"
•
저자: Jiwoo Hong et al. (KAIST)
•
•
설명: 참조 모델 없이 오즈비를 사용하는 단일형 선호도 최적화 알고리즘
3.2.6. XPO (Exploratory Preference Optimization)
•
논문: "Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF"
•
저자: Tengyang Xie et al.
•
•
설명: DPO에 탐색을 추가한 온라인 선호도 튜닝 방법
3.2.7. Mixed Preference Optimization
3.3. Reinforcement Learning with Human Feedback
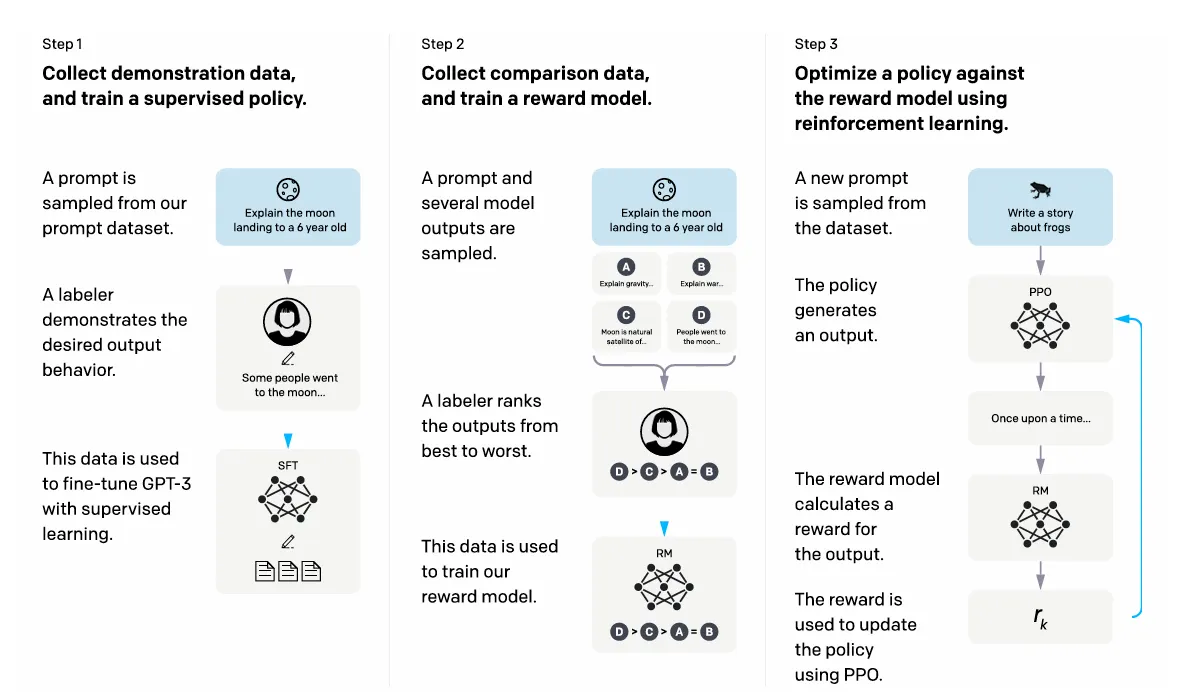
3.3.1. Reward Modeling
•
논문: "Secrets of RLHF in Large Language Models Part II: Reward Modeling"
•
저자: 다양한 연구팀
•
•
설명: RLHF에서 보상 모델 학습의 핵심 기법
3.3.2. PPO (Proximal Policy Optimization)
•
논문: "Proximal Policy Optimization Algorithms"
•
저자: John Schulman et al. (OpenAI)
•
•
설명: RLHF의 표준 알고리즘으로, 정책 경사 방법의 한 종류
3.3.3. PRM (Process Reward Model)
•
논문: "Let's Verify Step by Step"
•
저자: OpenAI 연구팀
•
•
설명: 중간 단계를 평가하는 프로세스 보상 모델
3.3.4. GRPO (Group Relative Policy Optimization)
•
논문: "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models"
•
저자: DeepSeek 연구팀
•
•
설명: PPO의 변형으로, 수학적 추론 능력을 향상시키기 위해 그룹 상대적 정책 최적화를 도입
3.3.5. RLOO (REINFORCE Leave-One-Out)
•
논문: "Revisiting REINFORCE Style Optimization for Learning from Human Feedback"
•
저자: 여러 연구팀
•
•
설명: Leave-One-Out 기법으로 불편 이점 기준선을 구성하는 REINFORCE 변형
3.4. Knowledge Distillation / Self-Play / Teacher–Student Methods
3.4.1. GKD (Generalized Knowledge Distillation)
•
논문: "On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes"
•
저자: Rishabh Agarwal et al.
•
•
설명: 자기회귀 시퀀스 모델을 위한 일반화된 지식 증류 프레임워크
4. Parameter-Efficient Fine-Tuning (PEFT)
대규모 언어 모델(LLM)과 비전-언어 모델(VLM)이 점점 커지면서, “전체 파라미터를 모두 업데이트하는” 기존 방식은 비효율적이 되었다. 수십억~수백억 개의 파라미터를 완전히 미세조정(full finetuning)하려면 막대한 VRAM·시간·데이터가 필요하고, 여러 작업(task)을 위해 모델을 반복해서 미세조정해야 한다면 저장 공간도 급격히 증가한다.
이러한 문제를 해결하기 위해 등장한 개념이 바로 PEFT(파라미터 효율적 미세조정)이다.
핵심 아이디어는 “전체 모델을 건드리지 않고, 아주 작은 일부 파라미터만 학습시키자”는 것이다.
4.1. Why PEFT?
PEFT가 필요한 이유는 다음과 같다.
1.
훈련 비용 감소
전체 모델을 업데이트하지 않고 극히 적은 파라미터만 조정하므로
GPU VRAM·학습 속도·메모리 사용량이 대폭 줄어듦
2.
원본 모델 보존
사전학습(pretrained) 모델은 그대로 유지하고,
추가로 학습한 파라미터만 “모듈”처럼 쌓을 수 있음.
3.
여러 도메인에 쉽게 전환 가능
도메인별 LoRA / Adapter / Prompt 파일만 바꿔 끼우면
하나의 베이스 모델로 여러 능력을 동시에 관리할 수 있음.
4.
누적 학습(continual learning)에 유리
이전 지식을 망가뜨리지 않으면서 새로운 능력을 추가할 수 있음
PEFT는 오늘날 거의 모든 LLM·VLM의 실제 서비스 적용에서 핵심 역할을 함.
4.2. 주요 PEFT 기법
4.2.1. LoRA (Low-Rank Adaptation)
LoRA는 PEFT의 대표적인 기법
핵심 아이디어는 “기존 가중치는 얼리고, 그 옆에 작은 저랭크(low-rank) 행렬을 추가해 학습하자”는 것이다.
•
Pretrained weight: 동결
•
LoRA weight (A, B 저랭크 행렬): 학습
장점
•
업데이트할 파라미터 수가 매우 적음
•
성능 유지력 높음
•
다양한 작업에 LoRA 파일만 갈아끼울 수 있음
실제로 LLaMA, Qwen, Mistral 기반 모델의 대부분이 LoRA로 도메인 확장 또는 instruction tuning을 한다.
4.2.2. QLoRA (Quantized LoRA)
QLoRA는 LoRA를 더욱 확장한 방식으로,
베이스 모델을 4-bit로 양자화(quantization)하여 VRAM을 극적으로 줄이는 것이 핵심이다.
•
Weight: 4-bit quantization
•
Update: LoRA 모듈만 학습
•
Optimizer: paged optimizer로 안정성 보완
효과
•
65B 같은 초대형 모델도 1~2장 GPU에서 튜닝 가능
•
소비자용 GPU로도 고성능 LLM fine-tuning 실현
실서비스에서 가장 많이 사용하는 PEFT 방식임
4.2.3. Adapter Layers
Adapter는 Transformer 블록 사이에 작은 병목(bottleneck) 레이어를 삽입하는 방식이다.
구조
•
다운프로젝션 → 비선형 → 업프로젝션
•
Adapter 레이어만 학습, 나머지 모델은 동결
특징
•
NLP·비전·멀티모달 전반에서 널리 사용
•
“Capability module”을 쌓아가는 방식으로 확장 가능
•
LoRA보다 구조적 변경이 더 명확한 편
특히 비전 모델(ViT)·음성 모델에서도 꾸준히 쓰이는 범용 PEFT 기술임
4.2.4. Prompt Tuning / Prefix Tuning (Instruction Tuning의 확장)
PEFT의 초경량 버전이라고 할 수 있음.
모델 파라미터는 그대로 두고, 입력 앞에 붙는 작은 벡터(soft prompt)만 학습한다.
종류
•
Prompt tuning: 입력 임베딩 앞에 학습된 벡터를 붙임
•
Prefix tuning: transformer 내부의 key/value prefix를 학습
•
Instruction tuning: 모델이 지시문을 잘 따르도록 SFT 데이터로 조정
특징
•
가장 가벼운 파라미터 업데이트 방식
•
domain adaptation, persona, style transfer 등에 적합
VLM에서는 시각 prompt를 통해 vision encoder 성능을 변경하기도 함
4.2.5. Context Window Extension
최근에는 모델 자체를 학습시키지 않고 PEFT 방식으로 position interpolation, rope scaling, multi-query attention 보강 등을 활용하여 컨텍스트 윈도우를 확장하기도 함
•
원본 모델은 동결
•
필요 파라미터(rope embedding 등)만 조정
•
32K → 128K → 1M token까지 확장 가능한 기술
이 역시 “전체 트레이닝 없이 특정 기능만 학습”한다는 점에서 PEFT 범주에 포함됨
4.2.6. Continual Learning with PEFT
PEFT는 누적 학습(continual learning) 상황에서 특히 유리함.
•
베이스 모델은 바꾸지 않고
•
새로운 작업마다 “LoRA/Adapter 모듈”만 추가
•
필요한 순간 해당 모듈만 로딩해 inference
이 방식은
“하나의 거대한 모델 → 여러 전문 능력을 갖춘 모델 집합”이라는
멀티에이전트·전문가 시스템 구조를 만드는 데 매우 유용