
Summary

Clustering
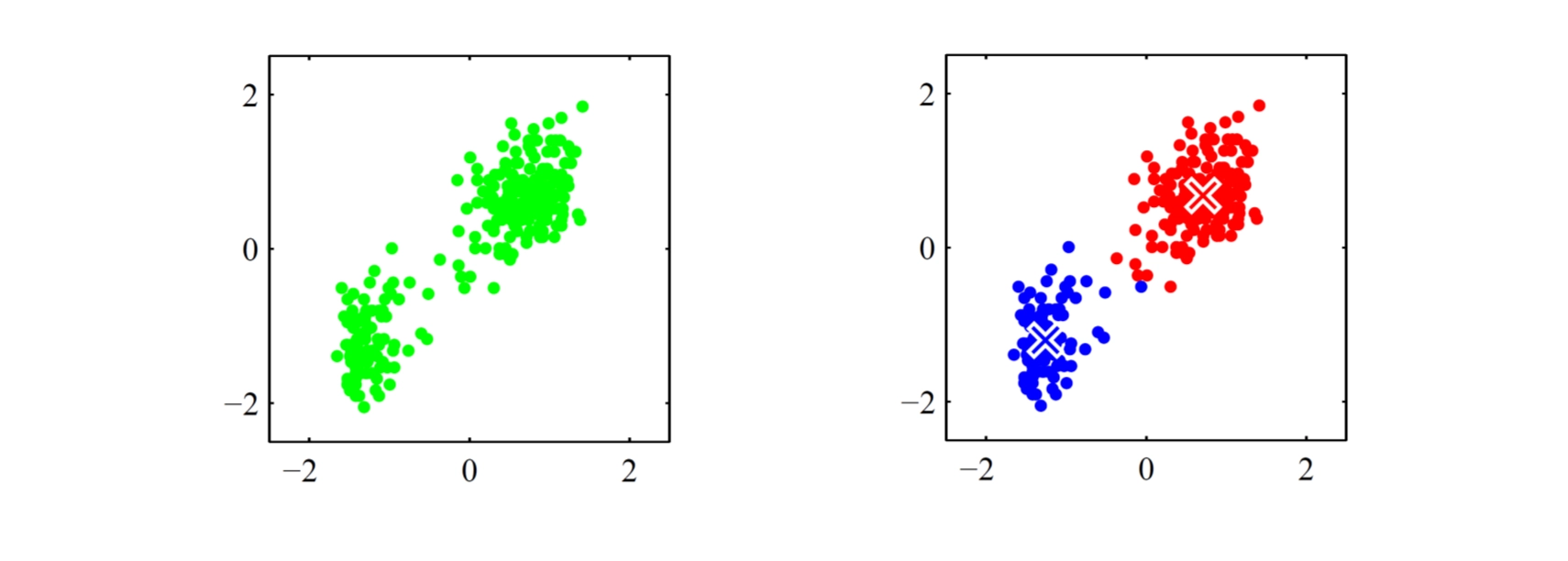
Given: a set of adata points (feature vectors) without labels
Output: group the data into some clusters, which means
•
assign each point to a specific cluster
•
find the center (representative / prototype / … ) of each cluster
•
Formal Definition
Given: data points and #clusters we want
Output: group the data into clusters, which means
•
find assignment for each data point and
such that
•
find the cluster centers
•
Example

•
Turn it into optimization problem
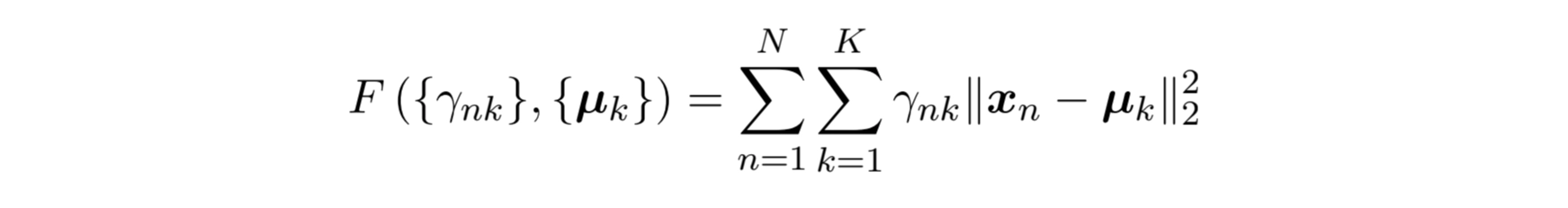
◦
using K-means Objective
◦
Alternative

◦
Closer Look


•
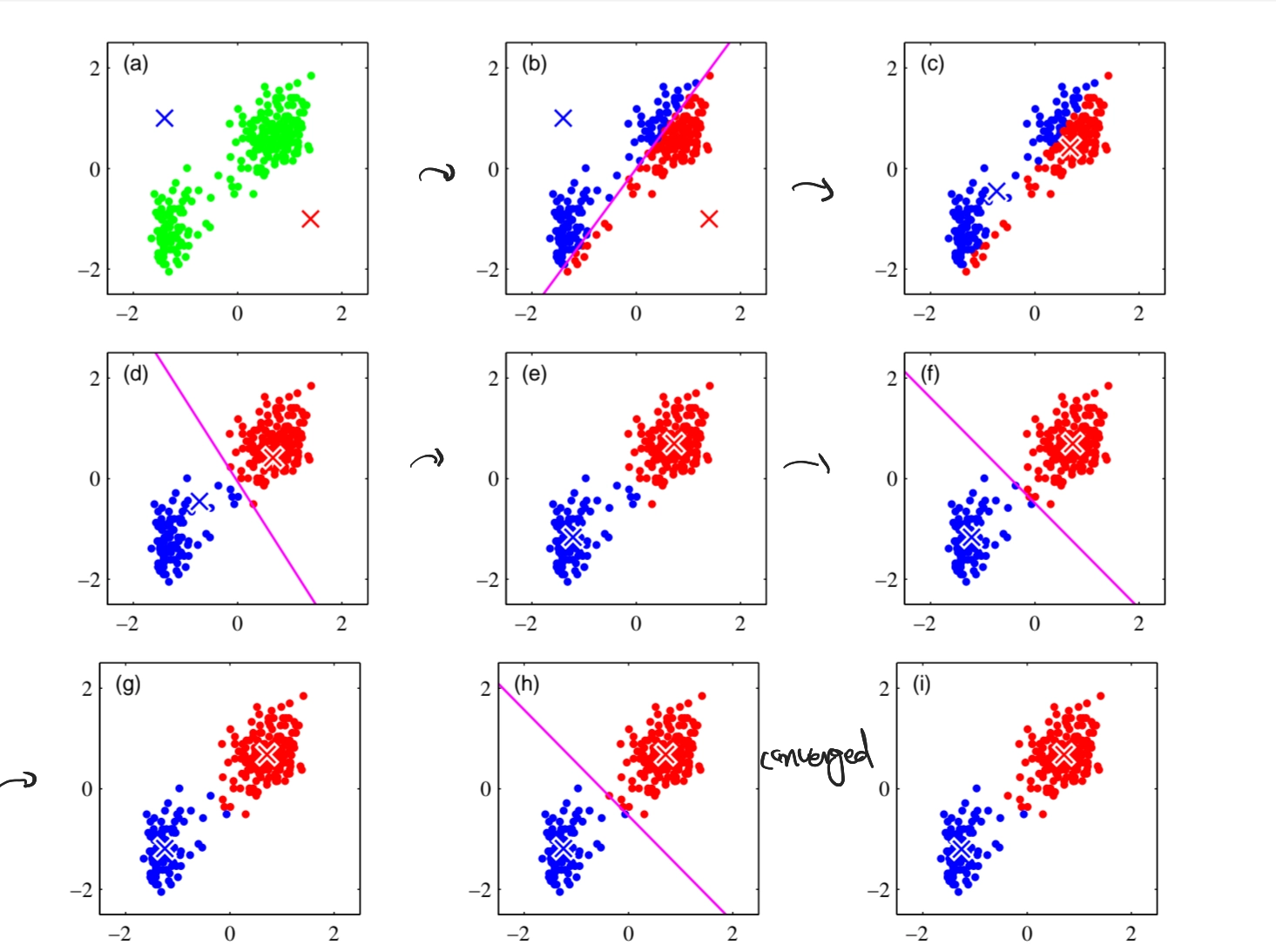
K-means Algorithm

•
How to initialize it?

◦
Why initialization matters?
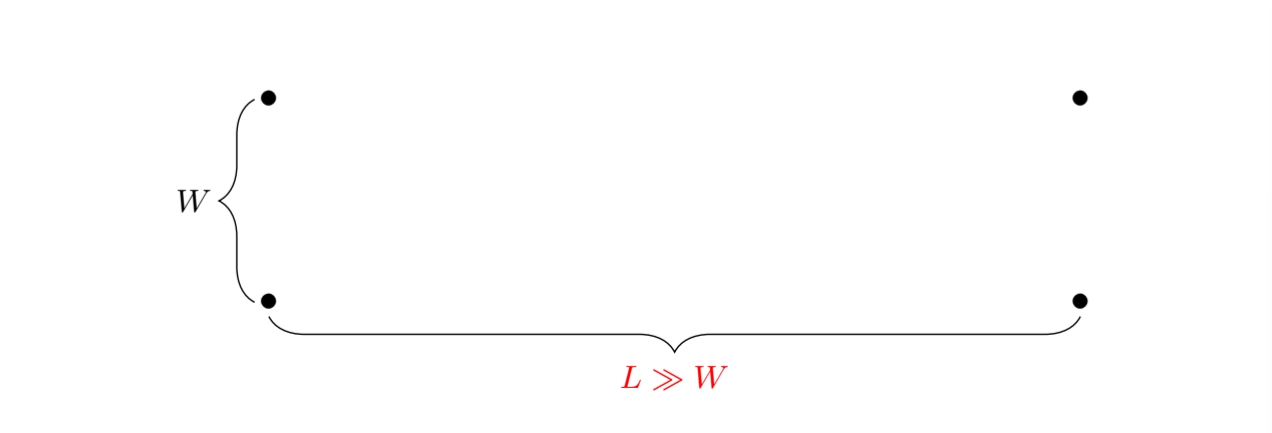
▪
Simple example: 4 data points, 2 clusters, 2 different initializations
•
randomly
•
Greedy Approach
•
K-means++

◦
expected K-means objective
Gaussian Mixture Model (GMM)
•
GMM is a probabilistic approach for clustering
◦
more explanatory than minimizing the K-means objective
◦
can be seen as a soft version of K-means
•
Expectation-Maximizatoin (EM) algorithm
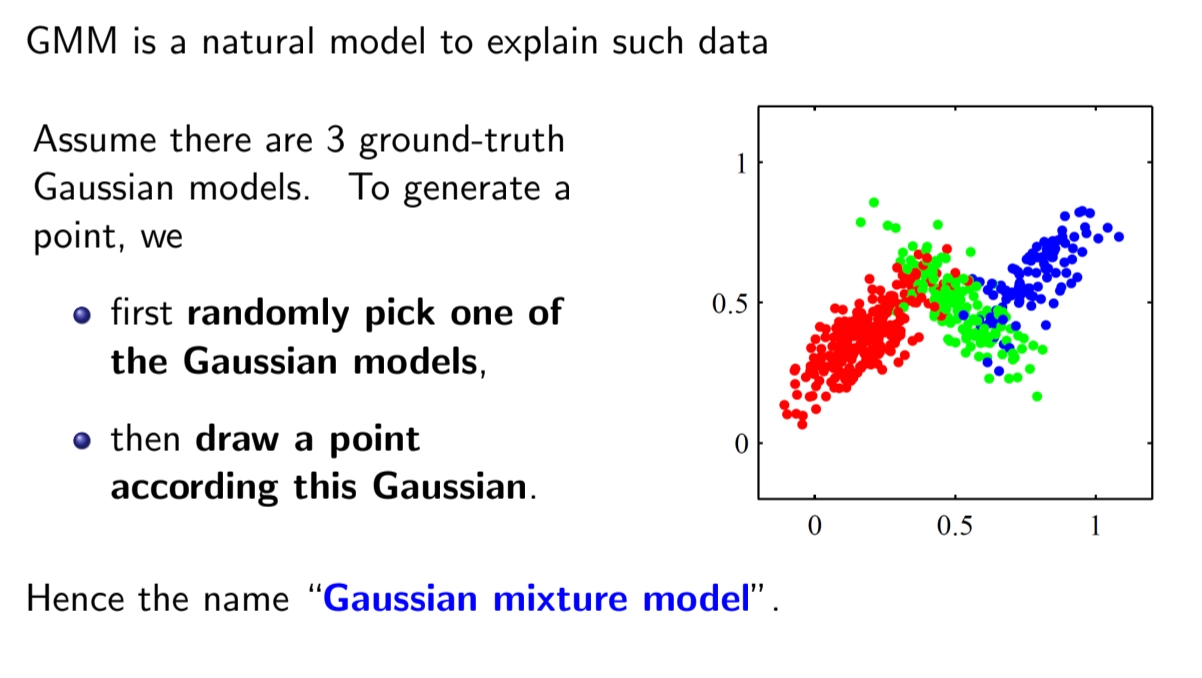
•
Formal Definition


Learning GMMs

•
How to learn Parameters?

EM Algorithm


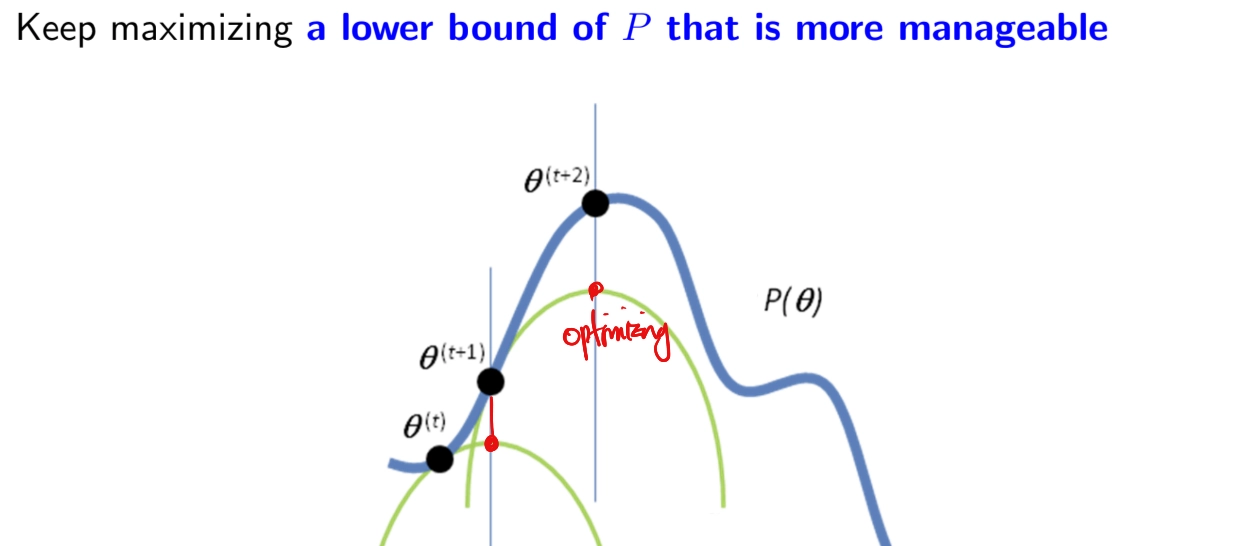
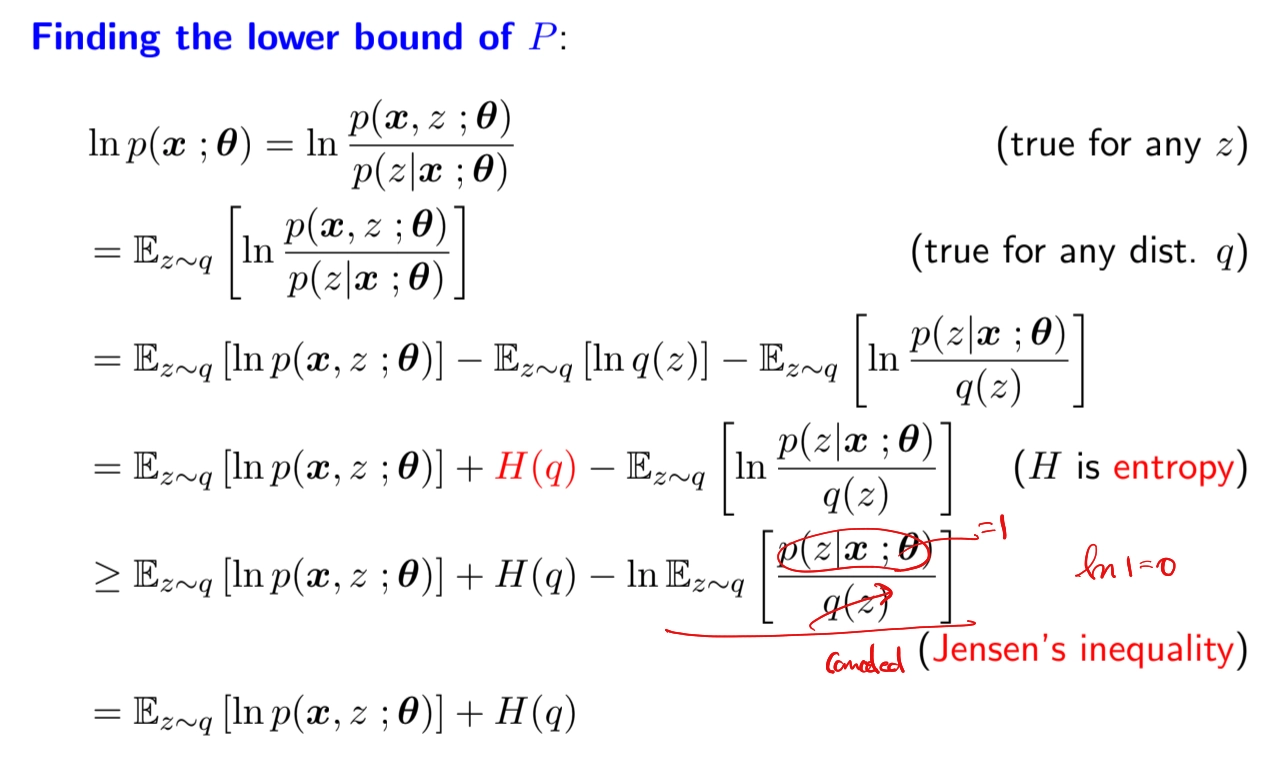


•
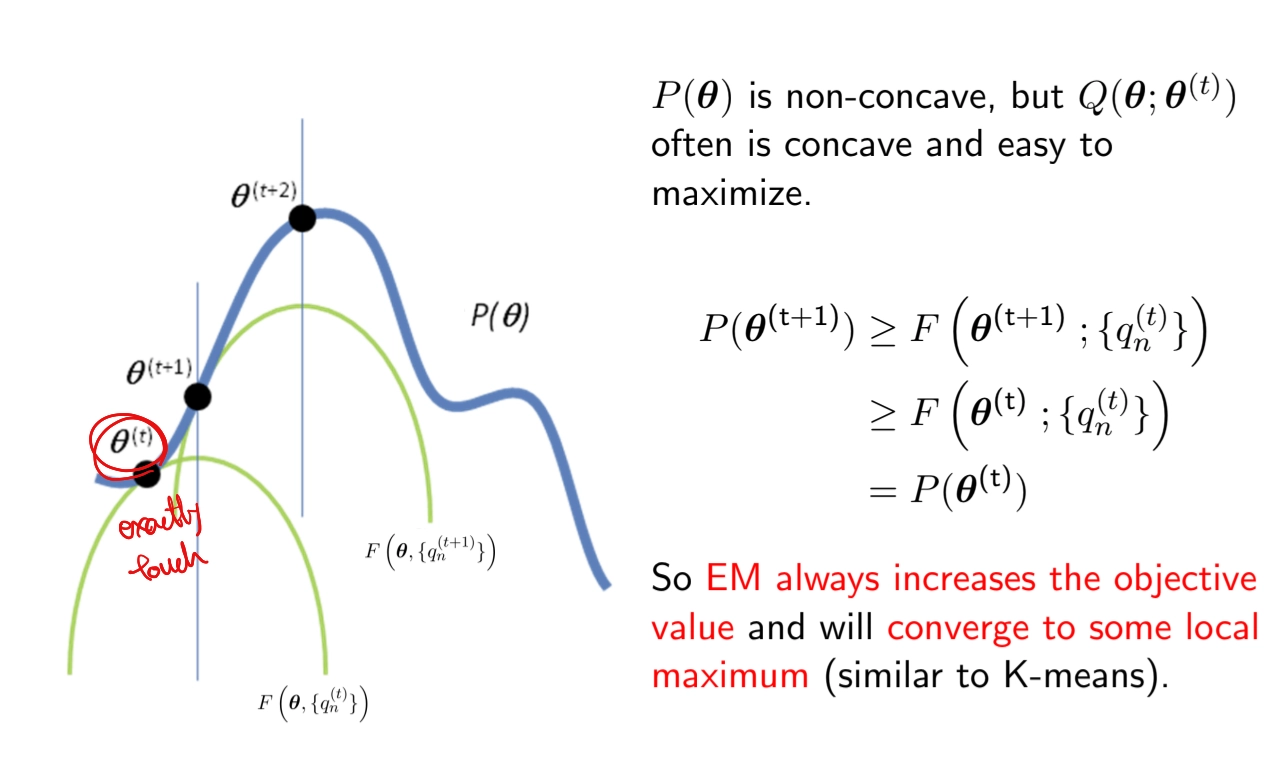


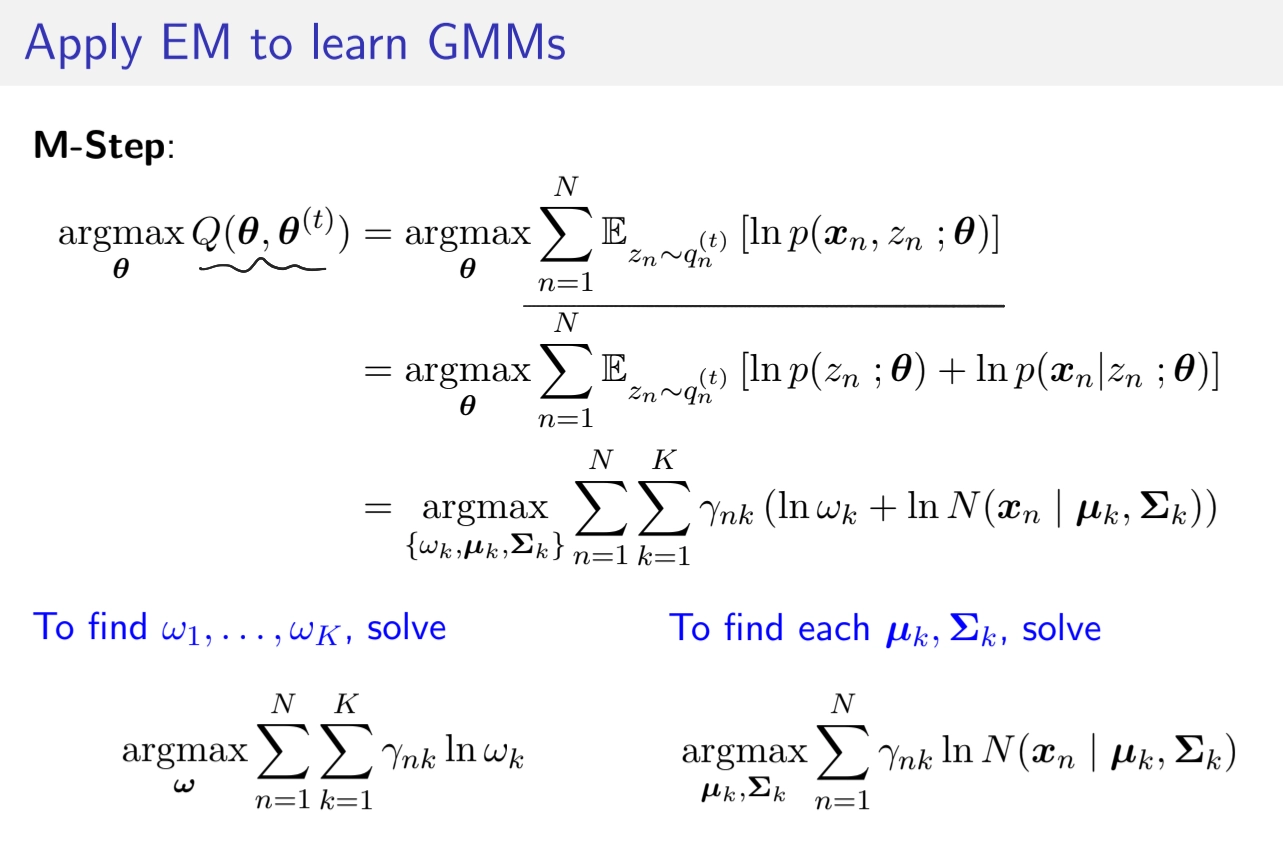
E-Step

M-Step

EM for Learning GMMs in total

GMM and K-means

List view
Search