
Insertion Sort (삽입 정렬)
개요

삽입 정렬 (Insertion Sort) 란 배열의 각 요소를 앞에서부터 차례대로 적절한 위치에 삽입하여 정렬하는 알고리즘으로, 시간 복잡도는 O(n²)이다.
삽입을 어떻게 하는가?
삽입 정렬은 그 이름에서 원리를 이미 알 수 있을 것이다. 하지만 삽입을 어디로 언제 해야하는가는 의문일 것이다.
삽입의 대상은 현재 처리 중인 요소로, 이미 정렬된 부분 배열에서 해당 요소가 들어갈 적절한 위치를 찾아 그 자리에 삽입한다. 삽입 위치를 찾기 위해 현재 요소보다 큰 값을 오른쪽으로 이동시키고 자리를 확보한 후에 요소를 삽입하는 방식이다.
삽입정렬(배열 A, 길이 n)
for i = 1 to n-1
key = A[i]
j = i - 1
while j >= 0 and A[j] > key
A[j + 1] = A[j]
j = j - 1
A[j + 1] = key
C++
복사
삽입 정렬의 동작 원리
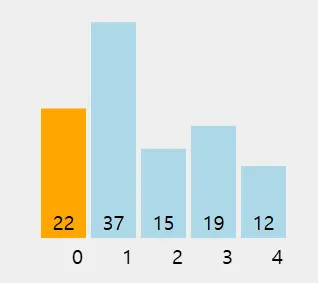
삽입 정렬이 배열 [22, 37, 15, 19, 12]에 적용되는 과정을 단계별로 설명하면 다음과 같다.
1.
첫 번째 요소 22는 이미 정렬된 것으로 간주한다. 따라서 두 번째 요소부터 비교를 시작한다.
2.
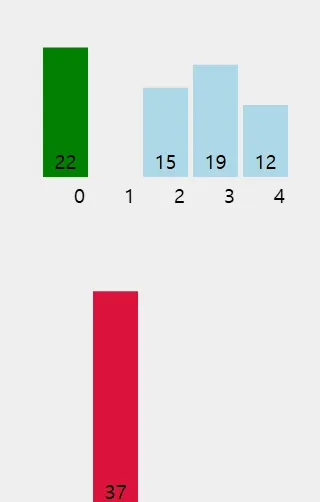
두 번째 요소 (37): 이미 정렬된 부분 [22]와 비교한다. 37은 22보다 크기 때문에 자신의 자리에 그대로 유지한다. 배열 상태는 [22, 37, 15, 19, 12]가 된다.
3.
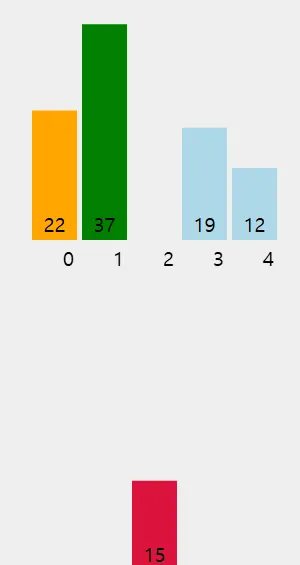
세 번째 요소 (15): 15를 앞의 정렬된 부분 [22, 37]에 삽입할 적절한 위치를 찾는다.

•
먼저 37과 비교한다. 15는 37보다 작으므로 37을 오른쪽으로 이동시킨다.
•
다음으로 22와 비교한다. 15는 22보다 작으므로 22도 오른쪽으로 이동시킨다.
•
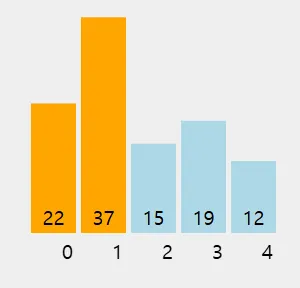
이제 15를 맨 앞에 삽입한다. 배열 상태는 [15, 22, 37, 19, 12]가 된다.
4.
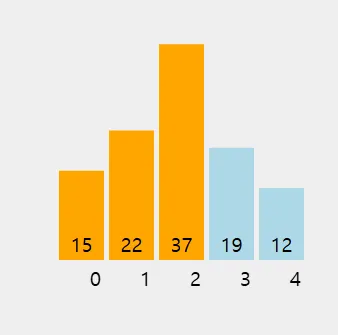
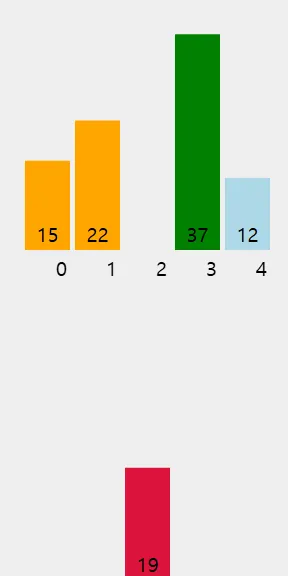
네 번째 요소 (19): 19를 앞의 정렬된 부분 [15, 22, 37]에 삽입할 적절한 위치를 찾는다.
•
먼저 37과 비교한다. 19는 37보다 작으므로 37을 오른쪽으로 이동시킨다.
•
다음으로 22와 비교한다. 19는 22보다 작으므로 22도 오른쪽으로 이동시킨다.

•
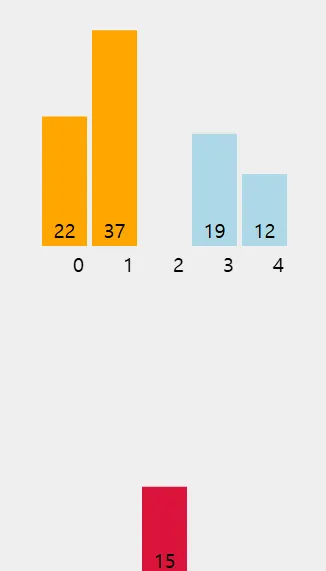
이제 19를 15와 22 사이에 삽입한다. 배열 상태는 [15, 19, 22, 37, 12]가 된다.
5.
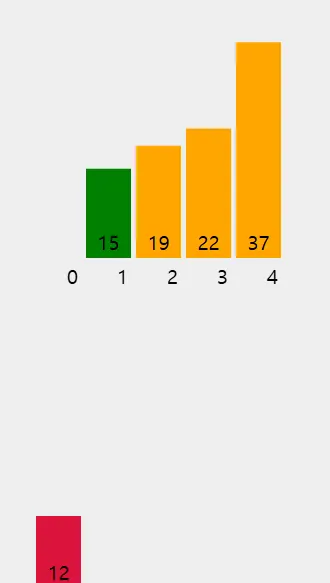
다섯 번째 요소 (12): 12를 앞의 정렬된 부분 [15, 19, 22, 37]에 삽입할 적절한 위치를 찾는다.
•
먼저 37과 비교한다. 12는 37보다 작으므로 37을 오른쪽으로 이동시킨다.
•
다음으로 22와 비교한다. 12는 22보다 작으므로 22도 오른쪽으로 이동시킨다.
•
그 다음 19와 비교한다. 12는 19보다 작으므로 19도 오른쪽으로 이동시킨다.
•
마지막으로 15와 비교한다. 12는 15보다 작으므로 15도 오른쪽으로 이동시킨다.
•
이제 12를 맨 앞에 삽입한다. 배열 상태는 [12, 15, 19, 22, 37]가 된다.
삽입 정렬 코드 (C++)
#include <iostream>
using namespace std;
void insertionSort(int arr[], int n) {
for (int i = 1; i < n; i++) {
int key = arr[i]; // 현재 삽입할 요소
int j = i - 1;
// key보다 큰 요소들을 오른쪽으로 한 칸씩 이동
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
// 적절한 위치에 key 삽입
arr[j + 1] = key;
}
}
void printArray(int arr[], int n) {
for (int i = 0; i < n; i++) {
cout << arr[i] << " ";
}
cout << endl;
}
int main() {
int arr[] = {22, 37, 15, 19, 12};
int n = sizeof(arr) / sizeof(arr[0]);
cout << "정렬 전 배열: ";
printArray(arr, n);
insertionSort(arr, n);
cout << "정렬 후 배열: ";
printArray(arr, n);
return 0;
}
C++
복사
추가적으로,
삽입 정렬은 이미 정렬된 데이터에 대해 최선의 효율을 보인다.
가령, 이미 정렬되있는 판매 순위가 있는 데이터들에서 새로운 점포들이 입점되어 판매 순위를 업데이트해야한다면 삽입 정렬로 빠르게 업데이트를 할 수 있다.
원리는 이렇다.
어떤 데이터를 꺼내어 왼쪽과 비교했을 때, 이미 왼쪽보다 크다면 왼쪽들과는 더이상 비교할 필요 자체가 없어진다. 이러면 왼쪽된 정렬된 그룹과 비교할 필요가 없어지므로 시간 복잡도는 이 된다.
다만 최악의 경우를 가정한 시간 복잡도가 크므로, 대용량 데이터 처리에는 절대 효율적이지 않다는 것만 염두해두면 좋을 것이다.
요약
•
삽입 정렬은 현재 요소를 앞의 정렬된 부분과 비교하여 적절한 위치에 삽입하며 배열을 점진적으로 정렬해 나간다.
•
삽입 정렬의 시간 복잡도는 이다.
•
이미 정렬된 데이터에 대해서는 최선의 효율을 보일 수 있는 알고리즘이다.
REFERENCES
Written by Changyu Lee, 2024-10-13